¡Llegamos al Día 16! Hoy conocerás al "rey de los bucles" en Python: el Bucle for.
A diferencia del while, que se repite "mientras" algo sea cierto, el bucle for está diseñado para recorrer colecciones (listas, tuplas, diccionarios o incluso palabras) de principio a fin.
🐍 Día 16: El Bucle for y la función range()
El reto de hoy consiste en aprender a iterar sobre una lista de elementos y generar secuencias de números automáticamente.
El Código del Reto
Python
>># 1. Recorrer una lista
>>lenguajes = ["Python", "JavaScript", "C++", "Java"]
>>print("Lista de lenguajes:")
>>for lenguaje in lenguajes:
>> print("- " + lenguaje)
>># 2. Usar la función range() para repetir algo n veces
>>print("\nContando del 0 al 4:")
>>for i inrange(5):
>> print(i)
>># 3. range(inicio, fin, salto)
>>print("\nNúmeros pares del 2 al 10:")
>>for n inrange(2, 11, 2):
>> print(n)
>>>
Lista de lenguajes:
- Python
- JavaScript
- C++
- Java
Contando del 0 al 4:
0
1
2
3
4
Números pares del 2 al 10:
2
4
6
8
10
💡 ¿Qué estamos aprendiendo hoy?
Iteración Directa: En Python, no necesitas un contador (como i++) para leer una lista. El for toma cada elemento y lo asigna a una variable temporal (en este caso, lenguaje) automáticamente.
La función range(): Es la mejor amiga del bucle for.
range(5) genera números del 0 al 4 (el 5 es exclusivo).
range(2, 11) genera del 2 al 10.
range(2, 11, 2) el tercer número indica el "paso" o salto.
Strings como Iterables: También puedes recorrer una palabra letra por letra: for letra in "Python": print(letra).
🚩 Diferencia clave con otros lenguajes
En lenguajes como C o Java, los bucles for suelen ser numéricos. En Python, el for es en realidad un "foreach", lo que hace que el código sea mucho más legible y natural, casi como leer una frase en inglés: "Para cada lenguaje en la lista de lenguajes, imprímelo".
¿Pasamos al Día 17?
En el Día 17, el reto suele centrarse en el Control de Bucles avanzado usando break y una nueva palabra clave: continue (que sirve para saltarse una repetición específica sin detener todo el bucle).
¡Llegamos al Día 15! Hoy entramos en el mundo de la iteración. Hasta ahora, tu código se ejecutaba de arriba abajo una sola vez. Con los bucles, puedes hacer que una parte de tu programa se repita tantas veces como sea necesario.
🐍 Día 15: El Bucle while (Mientras...)
El bucle while ejecuta un bloque de código mientras una condición sea verdadera. Es ideal para situaciones donde no sabes exactamente cuántas veces tendrás que repetir algo.
El Código del Reto
Python
>># 1. Contador simple
>>contador = 1>>while contador <= 5:
>> print("Contador vale:", contador)
>> contador += 1# ¡Súper importante! Incrementamos para no crear un bucle infinito
>>print("¡Bucle terminado!")
>># 2. Ejemplo interactivo (Pedir datos hasta que sea correcto)
>>clave = "">>while clave != "python123":
>> clave = input("Introduce la contraseña secreta: ")
>>print("Acceso concedido.")
La Condición: El bucle revisa la condición (contador <= 5) antes de cada repetición. Si es True, entra; si es False, salta al final.
Actualización de la variable: En el primer ejemplo, usamos contador += 1. Si olvidamos esto, el contador siempre valdría 1, la condición siempre sería verdadera y el programa se quedaría "colgado" en un bucle infinito.
Casos de uso: El while es perfecto para menús de aplicaciones, juegos (mientras el jugador tenga vidas) o validar entradas de usuario.
🚩 El concepto de break
A veces queremos salir de un bucle antes de que la condición principal cambie. Para eso usamos la palabra clave break.
Python
>>i = 1>>while i < 100:
>> print(i)
>> if i == 3:
>> break# Se detiene aquí, aunque 3 sea menor que 100
>> i += 1
>>>
1
2
3
¿Pasamos al Día 16?
En el Día 16, el reto suele presentar al "rey de los bucles" en Python: el Bucle for. Es mucho más común que el while porque se usa para recorrer listas, diccionarios y rangos de números de forma muy sencilla.
¿Te gustaría ver cómo funciona el bucle for en el Día 16?
¡Excelente! El Día 14 es el complemento perfecto para el día anterior. Si el if te permite tomar una decisión, los Operadores Lógicos te permiten tomar decisiones mucho más complejas combinando varias condiciones a la vez.
🐍 Día 14: Operadores Lógicos (and, or, not)
Estos operadores se utilizan para conectar sentencias condicionales. Son la base de la lógica de programación avanzada.
El Código del Reto
Python
>># Definimos algunas variables de estado
>>edad = 20
>>tiene_licencia = True
>>tiene_dinero = False>># 1. El operador AND (Ambas deben ser ciertas)>>if edad >= 18and tiene_licencia:
>> print("Puedes conducir legalmente.")
>># 2. El operador OR (Al menos una debe ser cierta)>>if tiene_dinero or tiene_licencia:
>> print("Tienes un medio para moverte.")
>># 3. El operador NOT (Invierte el valor de verdad)
>>es_fin_de_semana = False>>ifnot es_fin_de_semana:
>> print("¡A trabajar! Aún no es fin de semana.")
>>>
Puedes conducir legalmente.
Tienes un medio para moverte.
¡A trabajar! Aún no es fin de semana.
💡 ¿Qué estamos aprendiendo hoy?
and: Solo devuelve True si todas las condiciones son verdaderas. Si una falla, todo falla.
or: Devuelve True si al menos una de las condiciones es verdadera. Solo falla si todas son falsas.
not: Es un "interruptor". Si algo es True, lo vuelve False, y viceversa. Es muy útil para verificar si algo no ha sucedido.
Usuario: omc
Contraseña: 1234
Usuario o contraseña incorrectos
¿Pasamos al Día 15?
En el Día 15, el reto suele introducir el concepto de Bucles (Loops), específicamente el Bucle while. Esto permitirá que tu código repita una acción automáticamente hasta que se cumpla una condición (por ejemplo, pedir la contraseña hasta que sea correcta).
¿Te gustaría ver cómo funcionan los bucles en el Día 15?
¡Entramos en una de las partes más emocionantes de la programación! El Día 13 es cuando tu código deja de ser una lista de instrucciones fijas y empieza a tomar decisiones basadas en condiciones.
🐍 Día 13: Sentencias Condicionales (if, elif, else)
El reto de hoy es crear un programa que evalúe una situación y responda de manera distinta según el resultado. Para esto, usamos la lógica: "Si pasa esto, haz aquello; si no, haz esto otro".
El Código del Reto
Python
>># Definimos una variable para evaluar
>>puntuacion = 85>>if puntuacion >= 90:
>> print("Excelente: Sacaste una A")
>>elif puntuacion >= 80:
>> print("Muy bien: Sacaste una B")
>>elif puntuacion >= 70:
>> print("Bien: Sacaste una C")
>>else:
>> print("Necesitas mejorar: Sacaste una nota baja")
>>>
Muy bien: Sacaste una B
💡 ¿Qué estamos aprendiendo hoy?
La estructura if: Es la condición principal. Si es verdadera (True), se ejecuta el bloque de código de abajo.
elif (else if): Se usa para revisar otras condiciones si la primera fue falsa. Puedes poner tantos elif como necesites.
else: Es el "comodín". Se ejecuta solo si ninguna de las condiciones anteriores fue cierta.
Operadores de Comparación:
> (mayor que)
< (menor que)
== (igual a) — ¡Ojo! Doble signo igual para comparar.
!= (diferente de)
>= y <= (mayor o igual / menor o igual)
⚠️ ¡Cuidado con la Indentación!
A diferencia de otros lenguajes que usan llaves { }, Python usa el espaciado (sangría). Todo lo que esté movido hacia la derecha después de los dos puntos : es lo que se ejecutará si la condición se cumple. Si olvidas la sangría, Python te dará un IndentationError.
Un pequeño ejercicio rápido:
Intenta escribir un código que pida un número al usuario y diga si es Positivo, Negativo o Cero. (Recuerda usar int(input()) para recibir el número).
¿Continuamos con el Día 14?
En el Día 14, el reto suele introducir los Operadores Lógicos (and, or, not). Estos te permiten combinar condiciones, como: "Si tienes más de 18 años Y tienes licencia, puedes conducir".
¡Llegamos al Día 12! Hoy cerramos el bloque de las "4 grandes colecciones de datos" en Python. Ya conoces las listas, las tuplas y los diccionarios. El reto de hoy son los Sets (Conjuntos).
Un Set es como una bolsa de elementos donde no se permiten duplicados y el orden no importa. Es la herramienta perfecta cuando necesitas asegurar que cada dato sea único.
🐍 Día 12: Sets (Conjuntos Únicos)
Los sets se definen usando llaves {} (como los diccionarios), pero sin parejas de clave-valor.
El Código del Reto
Python
>># 1. Crear un Set (Fíjate que repetimos el '3')
>>mi_set = {1, 2, 3, 3, 4, 5}
>># 2. Ver el resultado (El duplicado habrá desaparecido)
>>print("Set original:", mi_set) # {1, 2, 3, 4, 5}>># 3. Agregar y eliminar elementos
>>mi_set.add(6)
>>mi_set.remove(1)
>># 4. Operaciones matemáticas de conjuntos
>>set_a = {1, 2, 3}
>>set_b = {3, 4, 5}
>># Unión (Une ambos sin repetir el 3)
>>print("Unión:", set_a | set_b) # {1, 2, 3, 4, 5}>># Intersección (Solo los que están en ambos)
>>print("Intersección:", set_a & set_b) # {3}
💡 ¿Qué estamos aprendiendo hoy?
Eliminación automática de duplicados: Si intentas añadir algo que ya existe, Python simplemente lo ignora. Es un truco muy usado para "limpiar" listas: lista_limpia = list(set(lista_sucia)).
No tienen orden: A diferencia de las listas, no puedes acceder a un elemento por su posición como mi_set[0]. Python te dará un error porque los elementos "flotan" dentro del conjunto.
Búsqueda ultra rápida: Buscar si un elemento existe dentro de un Set (if 3 in mi_set) es mucho más rápido que hacerlo en una lista, especialmente si tienes millones de datos.
🚩 Comparativa rápida de Colecciones:
Colección
Símbolo
¿Ordenada?
¿Mutable?
¿Duplicados?
Lista
[]
Sí
Sí
Sí
Tupla
()
Sí
No
Sí
Diccionario
{k:v}
Sí (3.7+)
Sí
Claves No
Set
{}
No
Sí
No
¿Pasamos al Día 13?
¡Felicidades! Has terminado la base de las estructuras de datos. A partir del Día 13, el curso suele dar un giro emocionante: la Lógica de Control. Empezaremos a usar el famoso if, para que tu programa pueda tomar decisiones por sí mismo.
¿Te gustaría ver cómo hacer que tu código "piense" con el Día 13?
¡Excelente elección! El Día 11 es uno de los más importantes porque introducimos los Diccionarios.
Si las listas son como estantes de libros numerados, los diccionarios son como una agenda de contactos: no buscas a alguien por su posición (el número 5 de la lista), sino por su nombre (la clave).
🐍 Día 11: Diccionarios (Estructura Clave-Valor)
Un diccionario es una colección de elementos donde cada dato tiene una etiqueta única llamada llave (key) y un contenido llamado valor (value).
>># Fuente: PPI Verifiquemos que persona sea un diccionario
>>print(type(persona))
>># 2. Acceder a un valor usando su clave
>>print("Nombre:", persona["nombre"])
>># 3. Modificar un valor
>>persona["ciudad"] = "Seattle">># 4. Agregar una nueva pareja clave-valor
>>persona["instrumento"] = "Guitarra">># 5. Obtener todas las llaves y todos los valores
>>print("Llaves:", persona.keys())
>>print("Valores:", persona.values())
>># 6. Ver todo el contenido (items)
>>print("Diccionario completo:", persona)
>>>
<class 'dict'>
Nombre: Eric Draven
Llaves: dict_keys(['nombre', 'banda', 'ciudad', 'instrumento'])
Valores: dict_values(['Eric Draven', "The Hangman's Joke", 'Seattle', 'Guitarra'])
Diccionario completo: {'nombre': 'Eric Draven', 'banda': "The Hangman's Joke",
'ciudad': 'Seattle', 'instrumento': 'Guitarra'}
💡 ¿Qué estamos aprendiendo hoy?
Claves Únicas: Las llaves (keys) no se pueden repetir. Si intentas crear dos llaves llamadas "nombre", la segunda borrará a la primera.
Sintaxis {llave: valor}: Es la estructura estándar. Las llaves suelen ser textos (strings), pero los valores pueden ser cualquier cosa: números, listas o incluso otros diccionarios.
Sin Orden Fijo (Históricamente): Aunque en las versiones más recientes de Python los diccionarios mantienen el orden de inserción, su propósito principal no es el orden, sino la rapidez de búsqueda.
Método .get(): Una forma profesional de acceder a los datos es persona.get("edad"). La ventaja es que si la llave "edad" no existe, el programa no se rompe (devuelve None).
🚩 Diferencia visual rápida:
Listas:[1, 2, 3] (Corchetes)
Tuplas:(1, 2, 3) (Paréntesis)
Diccionarios:{"uno": 1} (Llaves)
¿Pasamos al Día 12?
En el Día 12, el reto suele tratar sobre los Sets (Conjuntos). Son útiles para cuando necesitas una colección de elementos donde no se permitan duplicados (como una lista de correos electrónicos únicos).
¿Te gustaría ver el contenido del Día 12 o prefieres un ejercicio para practicar diccionarios?
MultiIndex: MultiIndex es un sistema de indexación jerárquico en pandas que permite una manipulación y almacenamiento de datos más complejos en DataFrames.
DataFrame: un DataFrame es una estructura de datos tabulares bidimensional, de tamaño variable y potencialmente heterogénea con ejes etiquetados (filas y columnas).
agg(): la función agg() aplica múltiples funciones de agregación a un DataFrame, lo que permite el análisis dinámico en ejes específicos.
groupby(): La función groupby() divide los datos en grupos según criterios específicos, lo que permite la aplicación de funciones independientes a cada grupo.
Ha descubierto que pandas es una biblioteca de Python que facilita la revisión y manipulación de datos tabulares. Además, groupby() y agg() son métodos esenciales de DataFrame que los profesionales de datos utilizan para agrupar, agregar, resumir y comprender mejor los datos. En esta lectura, revisará cómo funcionan estas funciones, así como cuándo y cómo aplicarlas.
groupby()
La función groupby() es un método que pertenece a la clase DataFrame. Funciona dividiendo los datos en grupos en función de criterios especificados, aplicando una función a cada grupo de forma independiente y, a continuación, combinando los resultados en una estructura de datos. Cuando se aplica a un marco de datos, la función devuelve un objeto groupby. Este objeto groupby sirve de base para diferentes operaciones de manipulación de datos, entre las que se incluyen:
Agregación: Cálculo de estadísticas de resumen para cada grupo
Transformación: Aplicar funciones a cada grupo y devolver los datos modificados
Filtración: Selección de grupos específicos en función de determinadas condiciones
Iteración: Iteración sobre grupos o valores
A continuación se muestran algunos ejemplos que utilizan la función groupby() en un marco de datos formado por diferentes prendas de vestir:
color mass_g price_usd type
0 red 125 20 pants
1 blue 440 35 shirt
2 green 680 50 shirt
3 blue 200 40 pants
4 green 395 100 shirt
5 red 485 75 pants
NOTA: es claro que para que se pueda construir el DataFrame anterior, la primera
instrucción debería ser importar el modulo pandas. >> import pandas as pd
Agrupando el marco de datos por type se obtiene un objeto DataFrameGroupBy:
>>grouped = clothes.groupby('type')
>>print(grouped)
>>print(type(grouped))
>>>
<pandas.core.groupby.DataFrameGroupBy object at 0x7f83f277a240>
<class 'pandas.core.groupby.DataFrameGroupBy'>
Sin embargo, se puede aplicar una función de agregación al objeto groupby:
>>grouped = clothes.groupby('type')
>>grouped.mean()
>>>
mass_g price_usd
type
pants 270.0 45.000000
shirt 505.0 61.666667
En el ejemplo anterior, groupby() combinaba todos los artículos en grupos basados en su tipo
y devolvía un objeto DataFrame que contenía la media de cada grupo para cada columna
numérica del marco de datos. Nota: En futuras versiones de pandas será necesario especificar
un parámetro numeric_only cuando se apliquen ciertas funciones de agregación
-como mean- a un objeto groupby. numeric_only se refiere al tipo de dato de cada columna.
En versiones anteriores de pandas (como la versión de esta plataforma) no es necesario
especificar numeric_only=True, pero en versiones futuras deberá hacerse.
En caso contrario, será necesario indicar las columnas concretas a capturar)
Además, se pueden crear grupos basados en varias columnas:
>>clothes.groupby(['type', 'color']).min()
>>> mass_g price_usd
type color
pants blue 200 40
red 125 20
shirt blue 440 35
green 395 50
En el ejemplo anterior, groupby() se invocó directamente en el marco de datos de ropa. Los datos se agruparon primero por type y luego por color. El resultado fueron cuatro grupos: el número de combinaciones de valores existentes para el tipo y el color. A continuación, se aplicó la función min() al resultado para filtrar cada grupo por su valor mínimo.
Para devolver simplemente el número de observaciones que hay en cada grupo, utilice el método size(). El resultado será un objeto Series con la información pertinente:
>>clothes.groupby(['type', 'color']).size()
>>>
type color
pants blue 1
red 2
shirt blue 1
green 2
dtype: int64
Funciones integradas de agregación
En los ejemplos anteriores se han mostrado las funciones de agregación mean(), min() y size() aplicadas a objetos groupby. Existen muchas funciones de agregación incorporadas. Algunas de las más utilizadas son:
count(): El número de valores no nulos en cada grupo
sum(): La suma de los valores de cada grupo
mean(): La media de los valores de cada grupo
median(): La mediana de los valores de cada grupo
min(): El valor mínimo de cada grupo
max(): El valor máximo de cada grupo
std(): La desviación típica de los valores en cada grupo
var(): La varianza de los valores de cada grupo
agg()
La función agg( ) es útil cuando se desea aplicar varias funciones a un marco de datos al mismo tiempo. agg() es un método que pertenece a la clase DataFrame. Significa "agregar" Sus parámetros más importantes son:
func: La función a aplicar
axis: El eje sobre el que aplicar la función (por defecto= 0).
A continuación se muestran algunos ejemplos de utilización de agg(). Observe que demuestran cómo puede utilizarse esta función por sí misma (sin groupby()). Observe también que, debido a limitaciones de la plataforma, algunos de los siguientes bloques de código no son ejecutables. En estos casos, la salida se proporciona como una imagen. A continuación se muestra de nuevo el marco de datos original clothes a modo de recordatorio:
>>clothes
>>>
color mass_g price_usd type
0 red 125 20 pants
1 blue 440 35 shirt
2 green 680 50 shirt
3 blue 200 40 pants
4 green 395 100 shirt
5 red 485 75 pants
El siguiente ejemplo aplica las funciones sum() y mean() a las columnas price y mass_g del marco de datos clothes.
Las dos columnas se subconjuntan del marco de datos antes de aplicar el método agg(). Si no subconjunta primero las columnas relevantes, agg() intentará aplicar sum() y mean() a todas las columnas, lo que no funcionaría porque algunas columnas contienen cadenas. (Técnicamente, sum() funcionaría, pero devolvería algo inútil porque simplemente combinaría todas las cadenas en una cadena larga)
Las funciones sum() y mean() se introducen como cadenas en una lista, sin sus paréntesis. Esto funcionará para cualquier función de agregación incorporada.
En el siguiente ejemplo, se aplican diferentes funciones a diferentes columnas.
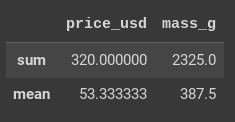
>>clothes.agg({'price_usd': 'sum',
'mass_g': ['mean', 'median']
})
>>>
Salida:
Observe lo siguiente:
Las columnas no son subconjuntos del marco de datos antes de aplicar la función agg(). Esto no es necesario porque las columnas se especifican en la propia función agg().
El argumento de la función agg() es un diccionario cuyas claves son las columnas y cuyos valores son las funciones que deben aplicarse a dichas columnas. Si se aplican varias funciones a una columna, se introducen como una lista. De nuevo, cada función integrada se introduce como una cadena sin paréntesis.
El marco de datos resultante contiene los valores NaN en los que no se ha designado una función determinada.
El siguiente ejemplo aplica las funciones sum() y mean() en todo el eje 1. En otras palabras, en lugar de aplicar las funciones en cada columna, se aplican en cada fila.
Las funciones groupby() y agg() suelen utilizarse juntas. En estos casos, aplique primero la función groupby() a un marco de datos y, a continuación, aplique la función agg() al resultado de la agrupación. Como referencia, aquí tiene de nuevo el marco de datos clothes.
>>clothes
>>>
color mass_g price_usd type
0 red 125 20 pants
1 blue 440 35 shirt
2 green 680 50 shirt
3 blue 200 40 pants
4 green 395 100 shirt
5 red 485 75 pants
En el siguiente ejemplo, los elementos de clothes se agrupan por color,
luego a cada uno de esos grupos se le aplican las funciones mean() y max() en las columnas
price_usd mass_g
mean max mean max
color
blue 37.5 40 320.0 440
green 75.0 100 537.5 680
red 47.5 75 305.0 485
Multiíndice
Es posible que haya observado que, cuando se aplican funciones a un objeto groupby, el marco de datos resultante tiene índices escalonados. Este es un ejemplo de MultiIndex. MultiIndex es un sistema jerárquico de indexación de marcos de datos. Permite almacenar y manipular datos con cualquier número de dimensiones en estructuras de datos de dimensiones inferiores, como series y marcos de datos. Esto facilita la manipulación de datos complejos.
Este curso no requiere un conocimiento profundo de la indexación jerárquica, pero es útil estar familiarizado con ella. Considere el siguiente ejemplo:
mass_g price_usd
mean min mean min
color type
blue pants 200.0 200 40.0 40
shirt 440.0 440 35.0 35
green shirt 537.5 395 75.0 50
red pants 305.0 125 47.5 20
Observe que color y type están situados más abajo que los nombres de las columnas
en la salida. Esto indica que color y type ya no son columnas, sino índices de filas con
nombre. Del mismo modo, observe que price_usd y mass_g se sitúan por encima de
mean y min en la salida de nombres de columnas, lo que indica un índice de columnas
jerárquico.
Si inspecciona el índice de filas, obtendrá un objeto MultiIndex que contiene información sobre los índices de filas:
Para realizar una selección en un marco de datos con un MultiIndex, utilice loc[] selection y ponga los índices entre paréntesis. A continuación se muestran algunos ejemplos en grouped, que es un marco de datos con un índice de fila de dos niveles y un índice de columna de dos niveles. Como referencia, aquí está el marco de datos grouped:
>>grouped
>>>
mass_g price_usd
mean min mean min
color type
blue pants 200.0 200 40.0 40
shirt 440.0 440 35.0 35
green shirt 537.5 395 75.0 50
red pants 305.0 125 47.5 20
Para seleccionar una columna de primer nivel (superior):
>>grouped.loc[:, 'price_usd']
>>>
mean min
color type
blue pants 40.0 40
shirt 35.0 35
green shirt 75.0 50
red pants 47.5 20
Para seleccionar una columna de segundo nivel (inferior):
>>grouped.loc[:, ('price_usd', 'min')]
>>>
color type
blue pants 40
shirt 35
green shirt 50
red pants 20
Name: (price_usd, min), dtype: int64
Para seleccionar una fila de primer nivel (más a la izquierda):
>>grouped.loc['blue', :]
>>>
mass_g price_usd
mean min mean min
type
pants 200.0 200 40.0 40
shirt 440.0 440 35.0 35
Para seleccionar una fila de nivel inferior (más a la derecha):
>>grouped.loc[('green', 'shirt'), :]
>>>
mass_g mean 537.5
min 395.0
price_usd mean 75.0
min 50.0
Name: (green, shirt), dtype: float64
color type mass_g price_usd
0 blue pants 200.0 40.0
1 blue shirt 440.0 35.0
2 green shirt 537.5 75.0
3 red pants 305.0 47.5
Observe que color y type ya no son índices de fila, sino columnas con nombre.
Los índices de fila son la enumeración estándar que empieza por cero.
De nuevo, no se espera que realice ninguna manipulación compleja de datos indexados jerárquicamente en este curso, pero es útil tener una comprensión básica de cómo funciona MultIndex, especialmente porque las manipulaciones de groupby() suelen dar como resultado un marco de datos MultiIndex por defecto.
Puntos clave
groupby() será una función esencial en tu trabajo como profesional de los datos, ya que permite combinar y analizar datos de forma eficaz. Del mismo modo, agg() le ayudará a aplicar múltiples funciones de forma dinámica en un eje específico de un marco de datos. Por sí solas o combinadas, estas herramientas ofrecen a los profesionales de los datos un acceso profundo a éstos y contribuyen al éxito de sus proyectos.