
Fuente: https://tinyurl.com/2ar5k4x8
Este artículo fue publicado como parte del Data Science Blogathon
Introducción
PDF significa formato de documento portátil. Utiliza la extensión .pdf. Este tipo de archivo se usa principalmente para compartir. No se pueden modificar, por lo que se conserva intacto el formato del archivo. Por lo tanto, se pueden compartir y descargar fácilmente. Están destinados a la lectura y no a la edición. Se ven similares en cualquier dispositivo en el que se abran, independientemente del hardware, el software y el sistema operativo. Por lo tanto, son el formato más utilizado. Fue inventado por Adobe . Ahora es un estándar abierto de la Organización Internacional de Normalización ( ISO ).
En este tutorial, aprenderemos a trabajar con archivos PDF en Python. Se tratarán los siguientes temas:
- Cómo extraer texto de un archivo PDF.
- Cómo rotar páginas de un archivo PDF.
- Cómo extraer información de un documento de un archivo PDF.
- Cómo dividir páginas de un archivo PDF.
- Cómo fusionar páginas de un archivo PDF.
- Cómo cifrar archivos PDF.
- Cómo agregar una marca de agua a un archivo PDF.
Algunas bibliotecas comunes para archivos PDF en Python
Hay muchas bibliotecas disponibles gratuitamente para trabajar con archivos PDF:
1. PDFMiner : es una herramienta de código abierto para extraer texto de PDF. Se utiliza para realizar análisis de los datos. También se puede utilizar como transformador de PDF o analizador de PDF.
2. PDFQuery : es un envoltorio ligero de python alrededor de PDFMiner, Ixml y PyQuery. Es una biblioteca de raspado de PDF rápida y fácil de usar.
3. Tabula.py : es un contenedor de python para tabula.java. Convierte archivos PDF en el marco de datos de Pandas y, además, todas las operaciones de manipulación de datos se pueden realizar en el marco de datos.
4. Xpdf : Permite la conversión de archivos PDF a texto.
5. pdflib : es una extensión de la biblioteca poppler con enlaces de python presentes en ella.
6. Slate : es un paquete de Python basado en PDFMiner y se utiliza para la extracción de texto de PDF.
7. PyPDF2 : es una biblioteca de python utilizada para realizar tareas importantes en archivos PDF, como extraer información específica del documento, fusionar archivos PDF, dividir las páginas de un archivo PDF, agregar marcas de agua a un archivo, cifrar y descifrar el PDF. archivos, etc. Usaremos la biblioteca PyPDF2 en este tutorial. Es una biblioteca de Python puro, por lo que puede ejecutarse en cualquier plataforma sin dependencias relacionadas con la plataforma en ninguna biblioteca externa.
Instalación de la biblioteca PyPDF2
Para instalar PyPDF2, copie los siguientes comandos en el símbolo del sistema y ejecútelo:
pip install PyPDF2
Obtener los detalles del documento
PyPDF2 proporciona metadatos sobre el documento PDF. Esta puede ser información útil sobre los archivos PDF. Información como el autor del documento, título, productor, Tema, etc. está disponible directamente.
.jpg)
Para extraer la información anterior, ejecute el siguiente código:
from PyPDF2 import PdfFileReader
pdf_path=r"C:UsersDellDesktopTesting Tesseractexample.pdf"
with open(pdf_path, 'rb') as f:
pdf = PdfFileReader(f)
information = pdf.getDocumentInfo()
number_of_pages = pdf.getNumPages()
print(information)
La salida del código anterior es la siguiente:

Formateemos la salida:
print("Author" +': ' + information.author)
print("Creator" +': ' + information.creator)
print("Producer" +': ' + information.producer)
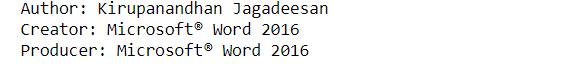
Extraer texto de PDF
Para extraer texto, leeremos el archivo y crearemos un objeto PDF del archivo.
# creando un objeto de archivo pdf
pdfFileObject = abrir (ruta_pdf, 'rb')
Luego crearemos un objeto de clase PDFReader y le pasaremos PDF File Object.
pdfReader = PyPDF2.PdfFileReader(pdfFileObject)
Y finalmente, extraeremos cada página y concatenaremos el texto de cada página.
texto=''
para i en rango (0, pdfReader.numPages):
# creando un objeto de página
pageObj = pdfReader.getPage(i)
# extrayendo texto de la página
text=texto+pageObj.extractText()
imprimir (texto)
El texto de salida es el siguiente:
Rotar las páginas de un PDF
Para rotar una página de un archivo PDF y guardarlo en otro archivo, copie el siguiente código y ejecútelo.
pdf_read = PdfFileReader(r"C:UsersDellDesktopstory.pdf")
pdf_write = PdfFileWriter()
# Girar la página 90 grados a la derecha
página1 = pdf_read.getPage(0).rotateClockwise(90)
pdf_write.addPage(página1)
con open(r'C:UsersDellDesktoprotate_pages.pdf', 'wb') como fh:
pdf_write.write(fh)

Combinar archivos PDF en Python
También podemos fusionar dos o más archivos PDF usando los siguientes comandos:
pdf_read = PdfFileReader(r”C:UsersDellDesktopstory.pdf”)
pdf_write = PdfFileWriter()
# Girar la página 90 grados a la derecha
página1 = pdf_read.getPage(0).rotateClockwise(90)
pdf_write.addPage(página1)
con open(r'C:UsersDellDesktoprotate_pages.pdf', 'wb') como fh:
pdf_write.write(fh)
El PDF de salida se muestra a continuación:

Dividir las páginas de PDF
Podemos dividir un PDF en páginas separadas y guardarlas nuevamente como PDF.
fname = os.path.splitext(os.path.basename(pdf_path))[0]
para la página en el rango (pdf.getNumPages()):
pdfwrite = PdfFileWriter()
pdfwrite.addPage(pdf.getPage(página))
nombre del archivo de salida = '{}_page_{}.pdf'.format(
fnombre, página+1)
con open(outputfilename, 'wb') como fuera:
pdfwrite.write(fuera)
print('Creado: {}'.format(nombre del archivo de salida))
pdf = PdfFileReader(ruta_pdf)
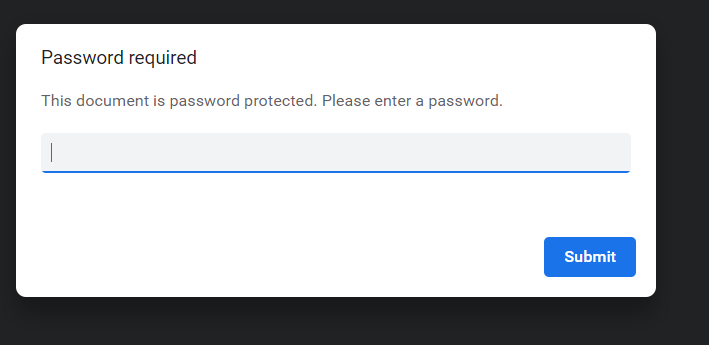
Cifrar un archivo PDF
El cifrado de un archivo PDF significa agregar una contraseña al archivo. Cada vez que se abre el archivo, se le solicita que proporcione la contraseña para el archivo. Permite que el contenido sea protegido con contraseña. Aparece la siguiente ventana emergente:
Podemos usar el siguiente código para lo mismo:
para la página en el rango (pdf.getNumPages()):
pdfwrite.addPage(pdf.getPage(página))
pdfwrite.encrypt(user_pwd=contraseña, propietario_pwd=Ninguno,
use_128bit=Verdadero)
con abierto (outputpdf, 'wb') como fh:
pdfwrite.write(fh)
Agregar una marca de agua al archivo PDF
Una marca de agua es
una imagen o patrón identificativo que aparece en cada página. Puede
ser el logotipo de una empresa o cualquier información sólida que se
refleje en cada página.
Para agregar una marca de agua a cada página del PDF, copie el siguiente código y ejecútelo.
archivo original = r"C:UsersDellDesktopTestingTesseractexample.pdf"
marca de agua = r"C:UsersDellDesktopTestingTesseractwatermark.pdf"
archivo de marca de agua = r"C:UsuariosDellDesktopTestingTesseractarchivodemarcadeagua.pdf"
marca de agua = PdfFileReader (marca de agua)
página de marca de agua = marca de agua.getPage(0)
pdf = PdfFileReader (archivo original)
pdfwrite = PdfFileWriter()
para la página en el rango (pdf.getNumPages()):
pdfpage = pdf.getPage(página)
pdfpage.mergePage (página de marca de agua)
pdfwrite.addPage(pdfpage)
con abierto (archivo con marca de agua, 'wb') como fh:
pdfwrite.write(fh)
El código anterior lee dos archivos: el archivo de entrada y la marca de agua. Luego, después de leer cada página, adjunta la marca de agua a cada página y guarda el nuevo archivo en la misma ubicación.

Notas finales
Como hemos visto anteriormente, todas las operaciones que se pueden pensar en un archivo PDF se pueden realizar fácilmente en Python utilizando la biblioteca PyPDF2. Está escrito puramente en Python. Por lo tanto, es completamente independiente de la plataforma. Es fácil de usar y proporciona una gran flexibilidad.
Nunca está de más decir:
¡Gracias por leer!
Fuente de imagen
- Imagen 1: https://monkeypen.com/pages/free-childrens-books
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.






No hay comentarios.:
Publicar un comentario