
Guía de referencia: Importar conjuntos de datos con Python
En tu carrera como profesional de los datos, te encontrarás con varios conjuntos de datos que tienen diferentes tipos de archivo o están almacenados en varias bases de datos. Como has aprendido anteriormente, es fundamental que sepas cuáles son estos tipos de datos y cómo importar datos utilizando Python. A continuación encontrarás ejemplos de importación a Python tanto de bases de datos a través de conexiones como de archivos de datos.
Aunque utilizarás la plataforma Coursera para codificar en Python, necesitarás saber cómo trabajar e importar Archivos CSV si quieres descargarlos y abrirlos fuera de Coursera.
Guardar este elemento del curso
Es posible que desee guardar una copia de esta guía para futuras consultas. Puede utilizarla como recurso para prácticas adicionales o en sus futuros proyectos profesionales. Para acceder a una versión descargable de este elemento del curso, haga clic en el siguiente enlace y seleccione "Usar plantilla."
Guía de referencia: Importar conjuntos de datos con Python
O
Si no tienes una cuenta de Google, puedes descargar el elemento directamente desde el archivo adjunto a continuación.
Cómo importar un conjunto de datos desde un Archivo CSV
Para este ejemplo, busca un Archivo CSV en tu ordenador. Si no dispone de uno, puede utilizar un conjunto de datos de empresas unicornio (empresas que alcanzaron una valoración de 1.000 millones de USD) de los Recursos de este curso.
Hay varias formas de importar un Archivo CSV a Python, pero sólo revisaremos algunas de las más comunes. Comience por utilizar una sentencia with y la función open(). Pasa el nombre del archivo (o la ruta del archivo) del Archivo CSV a la función open() junto con un argumento para el parámetro mode de la función.
with open("file path/file name", mode=)
Así que la sintaxis hasta ahora es
Nota: El siguiente bloque de código no es interactivo.
>>with open('file_path/file_name', mode=)
El modo le está diciendo a la librería Python qué hacer con el archivo. Cuando se define el modo, se utiliza una de las siguientes opciones:
'r' - read
'w' - escribir
'a' - añadir
'+' - crear nuevo archivo
Típicamente, estarás definiendo el modo dentro del campo de argumento with open() como 'r' porque quieres que Python abra y lea el Archivo CSV.
A continuación, añadiremos as file al final, para asignar el resultado a un nombre de variable. En este caso, la llamaremos data.
Nota: El siguiente bloque de código no es interactivo.
Importar un Archivo CSV usando pandas
En lugar de utilizar la biblioteca estándar de Python para leer un archivo, puedes utilizar pandas para importar el Archivo CSV en un marco de datos. Primero, por supuesto, querrás importar la librería pandas a tu notebook de Python.
>>import pandas as pd
A continuación, utilizará la función read_csv() para cargar los datos en un marco de datos. La Ruta de archivo entonces va en el campo de argumento.
>>df = pd.read_csv("file path/file name")
Nota: El siguiente bloque de código no es interactivo.
Cómo importar datos conectándose a una base de datos
Hay varias soluciones de bases de datos a las que te puedes conectar con Python, como BigQuery, MySQL, SQLite y Oracle. Las bases de datos son una forma cómoda para las empresas y organizaciones de almacenar grandes cantidades de datos.
Si el conjunto de datos es lo suficientemente pequeño, se puede descargar y manipular localmente en el ordenador. Sin embargo, a menudo los conjuntos de datos guardados en bases de datos son demasiado grandes para acceder a ellos en su totalidad en un ordenador personal. En este caso, existen varias opciones, la mayoría de las cuales consisten en consultar la base de datos con SQL para obtener tablas específicas de interés. En otras palabras, se extraen partes -normalmente filas y/o columnas concretas- de todo el conjunto de datos. La forma de realizar las consultas puede variar en función de los sistemas, plataformas e interfaces. Debido a esta variabilidad, esta guía de referencia sólo presentará un par de formas diferentes de consultar bases de datos. En concreto, explorará BigQuery, el almacén de datos de Google que proporciona una amplia gama de herramientas y servicios para facilitar el análisis.
Descarga de datos de BigQuery
Paso 1: Acceder a BigQuery
BigQuery permite cargar datos para su almacenamiento, y también dispone de una serie de conjuntos de datos públicos para explorar. Puede acceder a estos conjuntos de datos públicos de forma gratuita utilizando BigQuery Sandbox, que requiere una cuenta gratuita de Google. Sandbox te ofrece 10 GB de almacenamiento activo y 1 TB de datos de consulta procesados cada mes de forma gratuita.
Paso 2: Realizar una consulta
Una vez que hayas autenticado tu cuenta y creado un nuevo proyecto como se indica en las instrucciones enlazadas en el primer paso, estarás listo para realizar una consulta a una base de datos. Tenga en cuenta que si es la primera vez que inicia sesión, puede encontrar una ventana preguntando "¿Nuevo en BigQueryUI?" con un enlace a una guía de inicio rápido.
La guía de inicio rápido te guiará a través de los mismos pasos que los presentados aquí.
En la página "Bienvenido a tu espacio de trabajo SQL", haz clic en el botón "Crear una nueva consulta".
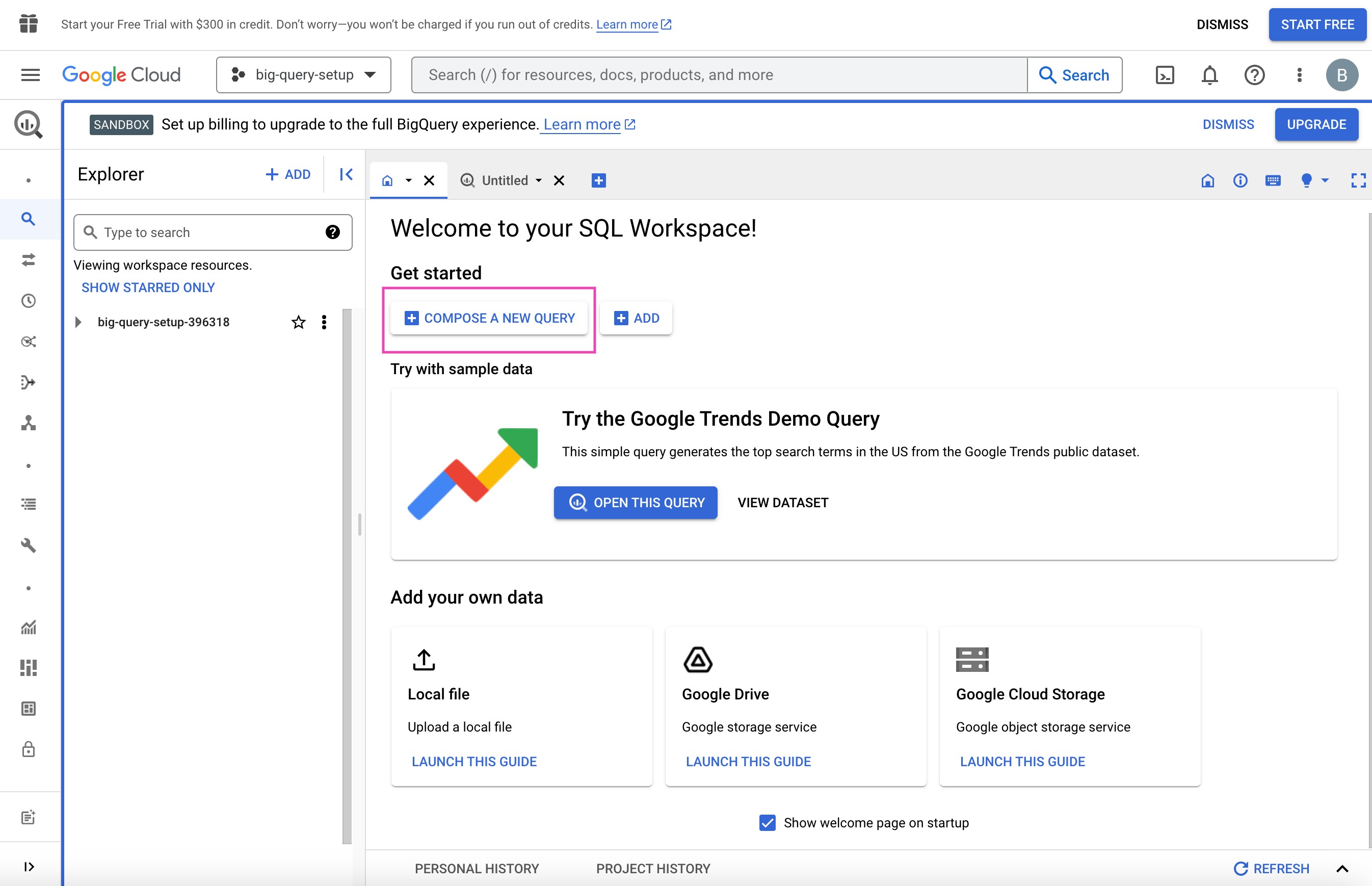
Haga clic en la barra de búsqueda del Explorador, en la parte izquierda de la página. Por ejemplo, puedes buscar "árboles" Inicialmente, esto devolverá cero resultados. Sin embargo, haga clic en "Buscar en todos los proyectos" y obtendrá los conjuntos de datos correspondientes del proyecto bigquery-public-data y las tablas preelaboradas a partir de esos conjuntos de datos.
Haga clic en la tabla street_trees del conjunto de datos san_francisco. Los metadatos de esta tabla aparecerán en un panel a la derecha. A continuación, haga clic en "Consultar" en el menú situado en la parte superior del panel de metadatos. Puede optar por realizar la consulta en una nueva pestaña o en un panel dividido de la ventana actual.
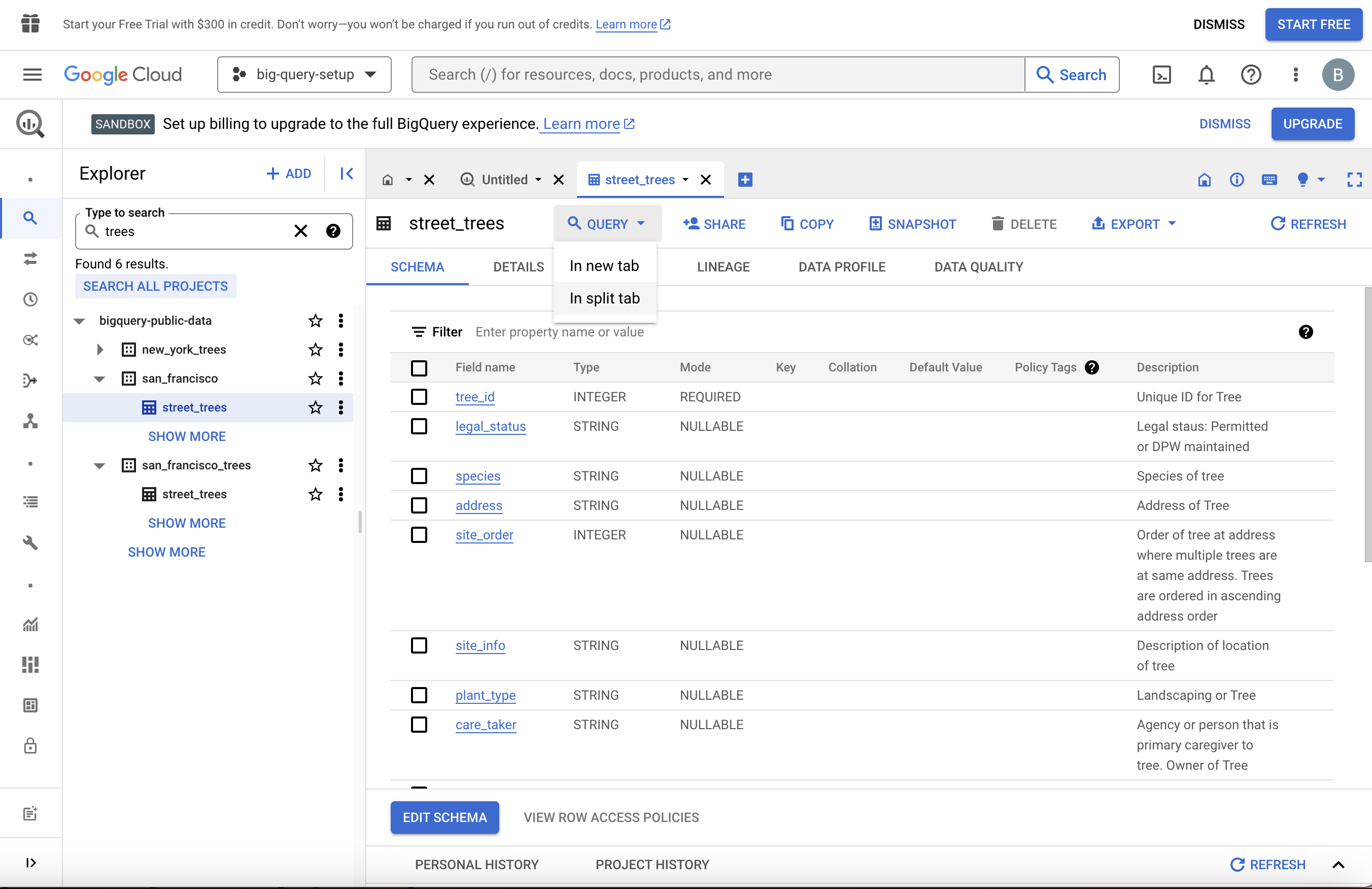
Ahora puede consultar la tabla utilizando SQL. Por ejemplo, la consulta de la siguiente captura de pantalla selecciona 5.000 filas con columnas de tree_id, plant_type, species, plant_date, y dbh - definidas como "profundidad, altura"

Una vez que esté satisfecho con su consulta, haga clic en el botón "Ejecutar" en la parte superior del panel de consulta SQL. Los resultados se mostrarán a continuación, y hay un botón para "Guardar resultados", que te permite guardar la tabla resultante en diferentes ubicaciones y formatos. A partir de ahí, puedes leer los datos en tu cuaderno.
Uso de Notebooks en BigQuery
Otra forma de acceder a los datos en BigQuery es utilizando las herramientas dentro de la propia plataforma BigQuery. Este flujo de trabajo se asemeja más al que utilizarían los profesionales de los datos cuando trabajan con conjuntos de datos muy grandes almacenados en la nube. Básicamente, se configura una máquina virtual en BigQuery. Una máquina virtual es un ordenador que tiene su propia CPU, memoria, software, etc., como cualquier otro ordenador, sólo que no tiene su propio hardware dedicado; a menudo existen como una partición en un servidor. Puede trabajar en un Notebook de Jupyter en la máquina virtual de la plataforma BigQuery, desde la que puede consultar y extraer datos directamente.
Este proceso requiere que configures un método de pago. Sin embargo, los nuevos usuarios obtienen un crédito de 300 dólares, y una instancia de ML cuesta sólo unos céntimos por minuto, por lo que tendrás aproximadamente 2.000 horas de uso gratuito antes de incurrir en ningún cargo. Hay un montón de tutoriales para configurar esto. Por ejemplo, si buscas "How to use Jupyter notebook in Google Cloud IA", encontrarás una serie de vídeos y blogs útiles sobre el tema.
Uso de Notebooks fuera de BigQuery
También es posible consultar datos en BigQuery desde cuadernos que no están en la plataforma BigQuery. Sin embargo, los detalles de este proceso dependen de varios factores, como la plataforma que aloja el cuaderno, el entorno operativo y la ubicación específica de los datos a los que se accede. Por lo tanto, no profundizaremos en este método. No obstante, siéntete libre de explorarlo por tu cuenta. Encontrarás muchos recursos útiles en línea que están a sólo una búsqueda de distancia.
Puntos clave
Existen muchos tipos diferentes de datos, lo que significa que hay numerosas formas de importar datos. Aprender varios métodos para importar datos, ya sea de un archivo de datos o de una base de datos, construirá una base sólida para tu carrera como profesional de los datos.
Recursos para obtener más información
Para aprender más sobre la importación de datos en Python, puedes consultar los siguientes enlaces:


No hay comentarios.:
Publicar un comentario