Splines
Por supuesto, la interpolación lineal por partes produce esquinas en los puntos de datos,
donde se unen las piezas lineales. Para producir una curva más suave, puede utilizar cúbica
splines, donde la curva de interpolación está hecha de piezas cúbicas con coincidencias
primera y segunda derivada. En el código, estos objetos se representan mediante el
CubicSpline instancias de clase. Una instancia se construye con el xy
y matrices de datos, y luego se pueden evaluar utilizando el objetivo xnew
valores:
from scipy.interpolate import CubicSpline
spl = CubicSpline([1, 2, 3, 4, 5, 6], [1, 4, 8, 16, 25, 36])
spl(2.5)
A CubicSpline objeto __call__ El método acepta tanto valores escalares como
matrices. Acepta también un segundo argumento, nu, para evaluar la
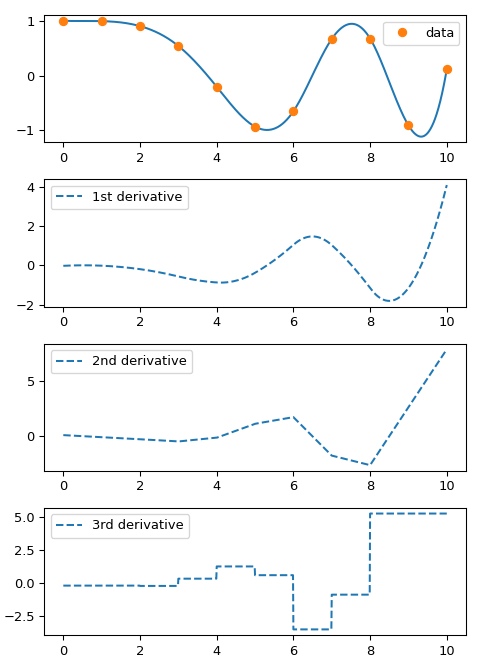
derivada de orden nu. Como ejemplo, trazamos las derivadas de un spline:
from scipy.interpolate import CubicSpline
x = np.linspace(0, 10, num=11)
y = np.cos(-x**2 / 9.)
spl = CubicSpline(x, y)
import matplotlib.pyplot as plt
fig, ax = plt.subplots(4, 1, figsize=(5, 7))
xnew = np.linspace(0, 10, num=1001)
ax[0].plot(xnew, spl(xnew))
ax[0].plot(x, y, 'o', label='data')
ax[1].plot(xnew, spl(xnew, nu=1), '--', label='1st derivative')
ax[2].plot(xnew, spl(xnew, nu=2), '--', label='2nd derivative')
ax[3].plot(xnew, spl(xnew, nu=3), '--', label='3rd derivative')
for j in range(4):
ax[j].legend(loc='best')
plt.tight_layout()
plt.show()