
Reemplazo de Matlab con Python - Parte 3: Historia y más información de datos
Estoy compartiendo cómo usé Python para completar la segunda parte de una tarea de ejemplo originalmente realizada con MATLAB. Aprendí más sobre cortar marcos de datos y hacer histogramas con dos bibliotecas diferentes.

Luis Medina

import plotly.graph_objects as go
from plotly.subplots import make_subplotsLo primero que debe hacer
importado la biblioteca es crear una figura a partir de la biblioteca de
objetos gráficos. Tuve que especificar de antemano que la cifra tendrá
ejes secundarios. Para hacer esto, paso a la función make_subplots
Un argumento que consiste en una lista de diccionarios (en este caso
solo uno, lo que indica que el eje secundario está habilitado). ¿Cómo
sabría eso? Muy simple, lo aprendí de la documentación .
fig = make_subplots(specs=[[{"secondary_y": True}]])Esto creó una figura, y ahora
puedo agregar rastros para la velocidad del vehículo y la presión del
freno. Quiero superponerlos, usando un eje X común (base de tiempo).
Para hacer esto, agregué dos trazas independientes, una para cada
variable, pero los datos para el eje X son los mismos para ambos.
# Add line plots fig.add_trace( go.Line(y=df1['Vehicle Speed'] ,x=df1.Time_s,name = 'Vehicle Speed'), secondary_y=False) fig.update_yaxes(title_text="Speed [km/h]", range=[0, 80], secondary_y=False) fig.add_trace( go.Line(y=df1['BrakeFront'] ,x=df1.Time_s,name = 'Brakes Pressure'), secondary_y=True) fig.update_yaxes(title_text="Pressure [bar]", range=[0, 50], secondary_y=True, color = 'red')
Observe que especificé la opción secondary_y=True para el segundo conjunto de datos (en este caso la presión). En Matlab, habría emitido un yyaxis right Comando justo antes de crear la trama de segunda línea. El procedimiento aquí es simplemente diferente.
A continuación, quería agregar líneas verticales para indicar los instantes que identifiqué como inicios de maniobras de frenado. Si la presión aumentaba repentinamente desde esos puntos, y la velocidad del vehículo era plausible para una maniobra de frenado, entonces los puntos identificados tienen sentido.
Para hacer las líneas, tuve que recurrir a un for-bucle esta vez:
for time in Brake_start1.Time_s: fig.add_shape(go.layout.Shape(type = "line", yref = "y", xref = "x", x0 = time, y0=0, x1 = time, y1 = 100))
Qué vergüenza por no tener un método mejor. Esto no me dejará dormir por la noche hasta que descubra cómo hacerlo de manera más eficiente. O tal vez no, ya veremos.
Para terminar, agregué algún formato con el siguiente código:
fig.update_xaxes(title_text="Time [s]", range = [700, 750] )
fig.update_layout(title = {
'text': '<b>Identified starts of braking maneuvers</b>',
'xanchor' : 'center',
'x' : 0.5, 'y': .95, 'font_size' : 12
},
showlegend=False)
fig¡El resultado se ve bastante bien! Y la trama interactiva se puede usar en sitios web,como este 😃 
Creación de histogramas con Plotly
¡DE ACUERDO! Los puntos identificados como comienzos de maniobras de frenado tienen sentido. Ahora es el momento de usar Plotly para hacer algunos histogramas.
Creé una figura y definí los contenedores comunes para usar. Observe que los contenedores se definen utilizando un diccionario:
#Create figure
fig = go.Figure()
#Define common bins
bins = dict(start= 10,
end= 100,
size= 5)
Luego, agregué los rastros y formateé la figura:
fig.add_trace(go.Histogram(x=Brake_start1['Vehicle Speed'],
xbins = bins,
histnorm='probability density',
opacity=0.9,
name = 'Driver 1'))
fig.add_trace(go.Histogram(x=Brake_start2['Vehicle Speed'],
xbins = bins,
histnorm='probability density',
opacity=0.7,
name = 'Driver 2'))
fig.update_layout(
title_text='<b>Vehicle speeds at the start of braking</b>',
xaxis_title_text='Vehicle speed [km/h]',
yaxis_title_text='Probability Density',
bargap=0.2,)
fig.show() 
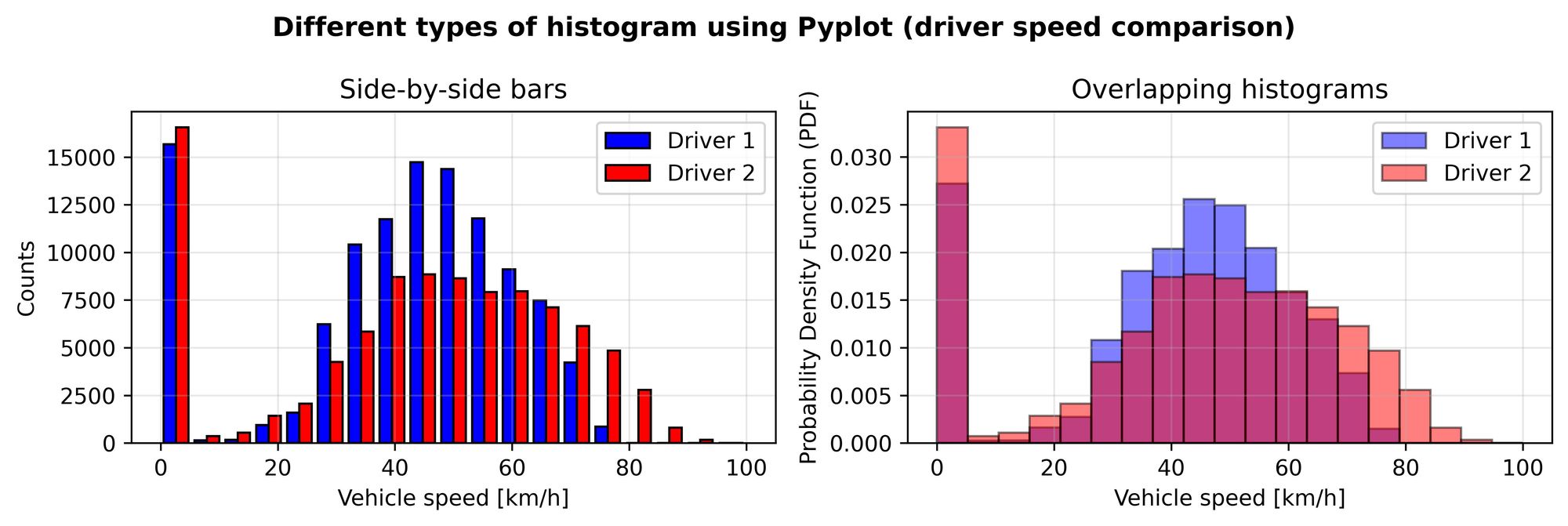
¡Los histogramas no mienten! Nuevamente, pero esta vez con Python, podemos ver que el primer conductor estaba frenando antes que el segundo. Aunque ambos alcanzaron velocidades de 80 km/h, parece que el primer conductor nunca hizo una maniobra de frenado por encima de 75 km/h. En cambio, el conductor 1 hizo un número significativamente mayor de maniobras de frenado entre 65 y 70 km/h; el pico para el conductor 2 es de alrededor de 75 - 80 km/h en su lugar.
Conclusión
Solo así, hemos completado la última parte de la publicación original que escribí sobre hacer esto con Matlab . Este fue un análisis muy simplificado o superficial, pero creo que fue un gran ejemplo de juguete para mí practicar y aprender más Python con algunas tareas específicas. Tuve que filtrar datos, indexar los marcos de datos, trazar datos de series de tiempo y crear diferentes tipos de histogramas. Incluso usé figuras con subtramas y ejes secundarios.
Estoy empezando a adoptar el hecho de que Python está destinado a usarse de una manera diferente, y las cosas son realmente más fáciles ahora que me concentro en aprender cómo usar el lenguaje para completar una tarea, en lugar de replicar exactamente lo que hice usando Matlab, especialmente cuando se trata de trazar datos. Si obtengo el mismo aspecto, entonces está bien. Si no lo hago, pero los resultados son decentes, no me enfatizo demasiado por el formato, a menos que sea estrictamente necesario.
Realmente disfruté haciendo esta serie de publicaciones, y espero que hayas encontrado algunas cosas útiles aquí. De todos modos, el reemplazo de Matlab con la serie Python no termina aquí, solo estoy haciendo algo de espacio para otros artículos que he preparado, y ciertamente agregaré otras publicaciones para esta serie en el futuro. Quizás más relacionado con el tema original de este blog, que en realidad está haciendo cosas. Ya veremos.
¡Gracias por leer esto y estad atentos para el próximo!
¡Salud!
La forma pitónica de hacer las cosas
Una de las cosas más populares de Python es su legibilidad. Cuando el idioma se usa correctamente, el código es más eficiente y casi se lee como inglés simple. La mejor manera de lograr esto es seguir un conjunto de pautas para el estilo de codificación, que se conocen como la "pitónica" . Intentaré aprender esto y aplicarlo a mi código a medida que avanza. Creo que te hace pensar más en términos de eficiencia del código y hacer un mejor uso del idioma.


No hay comentarios.:
Publicar un comentario