
Selección aleatoria en Python
En este artículo analizaremos cómo utilizar el módulo random de Python para seleccionar elementos de manera aleatoria de una lista
El módulo random de Python provee diferentes
herramientas para la selección pseudo-aleatoria de elementos dentro de
una lista o cadena. Esta selección puede ser configurada dependiendo de
la cantidad de elementos necesarios, la homogeneidad de probabilidad de
elegir cada elemento y si se requiere que los elementos puedan o no
repetirse en la selección.
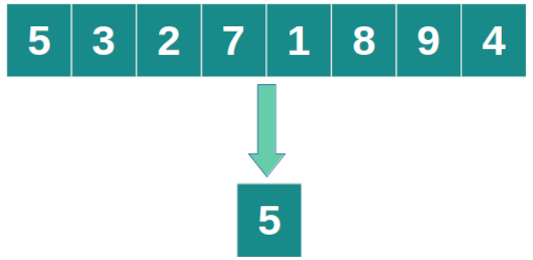
La función choice del módulo random devuelve un único elemento dentro de una secuencia de valores. Cada valor dentro de la secuencia tiene la misma probabilidad de ser seleccionados.
Si la secuencia es una cadena de caracteres el elemento seleccionado será uno de los caracteres.
>>import random>>random.choice('cadena_de_caracteres')>>#a
>>import random>>random.choice([12, 23, 45, 67, 65, 43])>>#43 >>import random>>random.choice(["Cadena","de","caracteres"])>>#de Selección de muestra con repeticiones
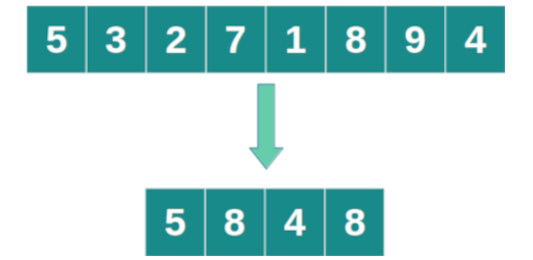
Cuando necesita obtener más de un elemento de una lista puede utilizarse el método choices. Este requiere la lista que contiene la población inicial desde la que se desean seleccionar los elementos y el valor k que representa la cantidad de elementos que desean seleccionar.
Esta función devuelve una muestra con la cantidad de elementos requeridos donde cada elemento tiene la misma probabilidad de ser seleccionado y un elemento puede formar parte de la muestra más de una vez.
>>import random>>poblacion = ["Alexa", "Ximena", "Michelle" ,"Jerónimo", "Francisco",>>"Cristóbal", "Máximo", "Pablo", "Agustina" , "Daniela"]>>muestra = random.choices(poblacion, k=5)>>#['Francisco', 'Máximo', 'Ximena', 'Pablo', 'Pablo']En este caso se puede observar que el elemento Pablo ha sido seleccionado dos veces para la muestra.
Si se requiere una probabilidad de selección diferente para cada elemento se necesita el atributo weights. Este argumento contiene una lista de valores numéricos representando la probabilidad relativa de cada elemento de la población.
>>import random
>>poblacion = ["Alexa", "Ximena", "Michelle" ,"Jerónimo", "Francisco",>>"Cristóbal", "Máximo", "Pablo", "Agustina" , "Daniela"]>>pesos = [5,1,2,3,1,3,5,5,10,15]>>muestra = random.choices(poblacion, weights=pesos, k=5)>>#['Cristóbal', 'Alexa', 'Daniela', 'Pablo', 'Daniela'] En este ejemplo el elemento Daniela ha sido
seleccionado dos veces ya que tiene el peso mayor y el resto de los
elementos de la muestra se corresponden a los valores de pesos más
altos.
Una opción diferente es utilizar pesos acumulativos en lugar de relativos. Los valores mostrados a continuación son equivalentes a los relativos mostrados en el ejemplo anterior.
>>import random
>>poblacion = ["Alexa", "Ximena", "Michelle" ,"Jerónimo", "Francisco",>>"Cristóbal", "Máximo", "Pablo", "Agustina" , "Daniela"]>>pesos = [10,2,4,6,2,6,10,10,20,30]>>muestra = random.choices(poblacion, cum_weights=pesos, k=5) Selección de muestra sin repeticiones
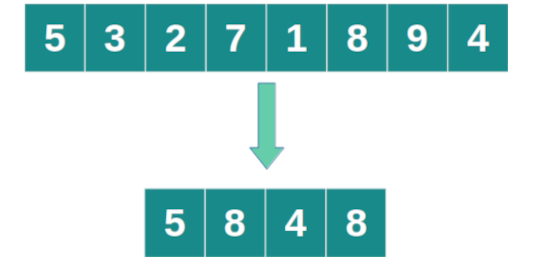
Si la muestra requerida de la población no debe repetir elementos de la población entonces se utiliza el método sample. Al igual que el método choices requiere una lista de la población sobre la que se creará la muestra y el argumento k indicando la cantidad de elementos seleccionados.
>>import random
>>poblacion = ["Alexa", "Ximena", "Michelle" ,"Jerónimo", "Francisco",>>"Cristóbal", "Máximo", "Pablo", "Agustina" , "Daniela"]>>random.sample(poblacion,k=5)>>#['Daniela', 'Michelle', 'Máximo', 'Jerónimo', 'Pablo'] range. Esto dará como resultado una lista de números sin repeticiones seleccionados aleatoriamente del rango.
>>import random>>random.sample(range(10),k=5)>># [8, 4, 5, 3, 7]
Barajar
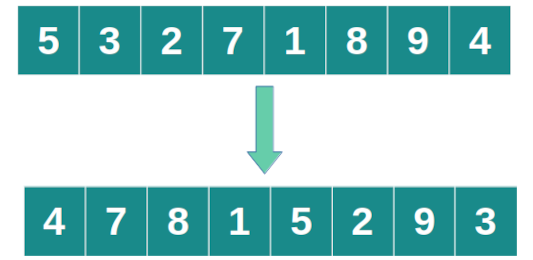
El método shuffle toma una lista de elementos y modifica
su orden de manera aleatoria. Es importante notar que no genera una
salida con el nuevo orden de los elementos sino que modifica la lista
existente.
>>import random>>poblacion = ["Alexa", "Ximena", "Michelle" ,"Jerónimo", "Francisco",>>"Cristóbal", "Máximo", "Pablo", "Agustina" , "Daniela"]>>random.shuffle(poblacion) 


No hay comentarios.:
Publicar un comentario