
Más sobre agrupación y agregación
Conceptos Clave
MultiIndex: MultiIndex es un sistema de indexación jerárquico en pandas que permite una manipulación y almacenamiento de datos más complejos en DataFrames.
DataFrame: un DataFrame es una estructura de datos tabulares bidimensional, de tamaño variable y potencialmente heterogénea con ejes etiquetados (filas y columnas).
agg(): la función agg() aplica múltiples funciones de agregación a un DataFrame, lo que permite el análisis dinámico en ejes específicos.
groupby(): La función groupby() divide los datos en grupos según criterios específicos, lo que permite la aplicación de funciones independientes a cada grupo.
Ha descubierto que pandas es una biblioteca de Python que facilita la revisión y manipulación de datos tabulares. Además, groupby() y agg() son métodos esenciales de DataFrame que los profesionales de datos utilizan para agrupar, agregar, resumir y comprender mejor los datos. En esta lectura, revisará cómo funcionan estas funciones, así como cuándo y cómo aplicarlas.
groupby()
La función groupby() es un método que pertenece a la clase DataFrame. Funciona dividiendo los datos en grupos en función de criterios especificados, aplicando una función a cada grupo de forma independiente y, a continuación, combinando los resultados en una estructura de datos. Cuando se aplica a un marco de datos, la función devuelve un objeto groupby. Este objeto groupby sirve de base para diferentes operaciones de manipulación de datos, entre las que se incluyen:
Agregación: Cálculo de estadísticas de resumen para cada grupo
Transformación: Aplicar funciones a cada grupo y devolver los datos modificados
Filtración: Selección de grupos específicos en función de determinadas condiciones
Iteración: Iteración sobre grupos o valores
A continuación se muestran algunos ejemplos que utilizan la función groupby() en un marco de datos formado por diferentes prendas de vestir:
Además, se pueden crear grupos basados en varias columnas:
>>clothes.groupby(['type', 'color']).min()
>>> mass_g price_usd type color pants blue 200 40 red 125 20 shirt blue 440 35 green 395 50
En el ejemplo anterior, groupby() se invocó directamente en el marco de datos de ropa. Los datos se agruparon primero por type y luego por color. El resultado fueron cuatro grupos: el número de combinaciones de valores existentes para el tipo y el color. A continuación, se aplicó la función min() al resultado para filtrar cada grupo por su valor mínimo.
Para devolver simplemente el número de observaciones que hay en cada grupo, utilice el método size(). El resultado será un objeto Series con la información pertinente:
>>clothes.groupby(['type', 'color']).size()
>>>
type color pants blue 1 red 2 shirt blue 1 green 2 dtype: int64
Funciones integradas de agregación
En los ejemplos anteriores se han mostrado las funciones de agregación mean(), min() y size() aplicadas a objetos groupby. Existen muchas funciones de agregación incorporadas. Algunas de las más utilizadas son:
count(): El número de valores no nulos en cada grupo
sum(): La suma de los valores de cada grupo
mean(): La media de los valores de cada grupo
median(): La mediana de los valores de cada grupo
min(): El valor mínimo de cada grupo
max(): El valor máximo de cada grupo
std(): La desviación típica de los valores en cada grupo
var(): La varianza de los valores de cada grupo
agg()
La función agg( ) es útil cuando se desea aplicar varias funciones a un marco de datos al mismo tiempo. agg() es un método que pertenece a la clase DataFrame. Significa "agregar" Sus parámetros más importantes son:
func: La función a aplicar
axis: El eje sobre el que aplicar la función (por defecto= 0).
A continuación se muestran algunos ejemplos de utilización de agg(). Observe que demuestran cómo puede utilizarse esta función por sí misma (sin groupby()). Observe también que, debido a limitaciones de la plataforma, algunos de los siguientes bloques de código no son ejecutables. En estos casos, la salida se proporciona como una imagen. A continuación se muestra de nuevo el marco de datos original clothes a modo de recordatorio:
>>clothes
>>>
color mass_g price_usd type 0 red 125 20 pants 1 blue 440 35 shirt 2 green 680 50 shirt 3 blue 200 40 pants 4 green 395 100 shirt 5 red 485 75 pants
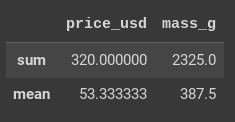
El siguiente ejemplo aplica las funciones sum() y mean() a las columnas price y mass_g del marco de datos clothes.
>>clothes[['price_usd', 'mass_g']].agg(['sum', 'mean'])
>>>
Salida:
Observe lo siguiente:
Las dos columnas se subconjuntan del marco de datos antes de aplicar el método agg(). Si no subconjunta primero las columnas relevantes, agg() intentará aplicar sum() y mean() a todas las columnas, lo que no funcionaría porque algunas columnas contienen cadenas. (Técnicamente, sum() funcionaría, pero devolvería algo inútil porque simplemente combinaría todas las cadenas en una cadena larga)
Las funciones sum() y mean() se introducen como cadenas en una lista, sin sus paréntesis. Esto funcionará para cualquier función de agregación incorporada.
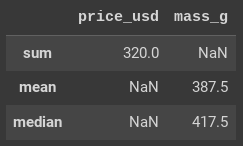
En el siguiente ejemplo, se aplican diferentes funciones a diferentes columnas.
>>clothes.agg({'price_usd': 'sum',
Observe lo siguiente:
Las columnas no son subconjuntos del marco de datos antes de aplicar la función agg(). Esto no es necesario porque las columnas se especifican en la propia función agg().
El argumento de la función agg() es un diccionario cuyas claves son las columnas y cuyos valores son las funciones que deben aplicarse a dichas columnas. Si se aplican varias funciones a una columna, se introducen como una lista. De nuevo, cada función integrada se introduce como una cadena sin paréntesis.
El marco de datos resultante contiene los valores NaN en los que no se ha designado una función determinada.
El siguiente ejemplo aplica las funciones sum() y mean() en todo el eje 1. En otras palabras, en lugar de aplicar las funciones en cada columna, se aplican en cada fila.
>>clothes[['price_usd', 'mass_g']].agg(['sum', 'mean'], axis=1)
Salida:

groupby() con agg()
Las funciones groupby() y agg() suelen utilizarse juntas. En estos casos, aplique primero la función groupby() a un marco de datos y, a continuación, aplique la función agg() al resultado de la agrupación. Como referencia, aquí tiene de nuevo el marco de datos clothes.
Es posible que haya observado que, cuando se aplican funciones a un objeto groupby, el marco de datos resultante tiene índices escalonados. Este es un ejemplo de MultiIndex. MultiIndex es un sistema jerárquico de indexación de marcos de datos. Permite almacenar y manipular datos con cualquier número de dimensiones en estructuras de datos de dimensiones inferiores, como series y marcos de datos. Esto facilita la manipulación de datos complejos.
Este curso no requiere un conocimiento profundo de la indexación jerárquica, pero es útil estar familiarizado con ella. Considere el siguiente ejemplo:
Si inspecciona el índice de filas, obtendrá un objeto MultiIndex que contiene información sobre los índices de filas:
>>grouped.index
>>>
MultiIndex(levels=[['blue', 'green', 'red'], ['pants', 'shirt']], labels=[[0, 0, 1, 2], [0, 1, 1, 0]], names=['color', 'type'])
El índice de columna muestra un objeto MultiIndex que contiene información sobre los índices de columna:
>>grouped.columns
>>>
MultiIndex(levels=[['mass_g', 'price_usd'], ['mean', 'min']], labels=[[0, 0, 1, 1], [0, 1, 0, 1]])
Para realizar una selección en un marco de datos con un MultiIndex, utilice loc[] selection y ponga los índices entre paréntesis. A continuación se muestran algunos ejemplos en grouped, que es un marco de datos con un índice de fila de dos niveles y un índice de columna de dos niveles. Como referencia, aquí está el marco de datos grouped:
>>grouped
>>>
mass_g price_usd mean min mean min color type blue pants 200.0 200 40.0 40 shirt 440.0 440 35.0 35 green shirt 537.5 395 75.0 50 red pants 305.0 125 47.5 20
Para seleccionar una columna de primer nivel (superior):
De nuevo, no se espera que realice ninguna manipulación compleja de datos indexados jerárquicamente en este curso, pero es útil tener una comprensión básica de cómo funciona MultIndex, especialmente porque las manipulaciones de groupby() suelen dar como resultado un marco de datos MultiIndex por defecto.
Puntos clave
groupby() será una función esencial en tu trabajo como profesional de los datos, ya que permite combinar y analizar datos de forma eficaz. Del mismo modo, agg() le ayudará a aplicar múltiples funciones de forma dinámica en un eje específico de un marco de datos. Por sí solas o combinadas, estas herramientas ofrecen a los profesionales de los datos un acceso profundo a éstos y contribuyen al éxito de sus proyectos.


No hay comentarios.:
Publicar un comentario