
Guía de referencia: Limpieza de datos en Python
Esta guía de referencia contiene funciones y métodos comunes que los profesionales de los datos utilizan para limpiar los datos. La guía de referencia contiene tres tablas diferentes de herramientas útiles, cada una agrupada por categoría de limpieza: datos que faltan, valores atípicos y codificación de etiquetas.
Guardar este tema del curso
Es posible que desee guardar una copia de esta guía para futuras consultas. Puede utilizarla como recurso para practicar más o en sus futuros proyectos profesionales. Para acceder a una versión descargable de este elemento del curso, haga clic en el siguiente enlace y seleccione "Usar plantilla".
Guía de referencia: Limpieza de datos en Python
O
Si no dispone de una cuenta de Google, puede descargar el elemento directamente desde el siguiente archivo adjunto.
Datos que faltan
Las siguientes funciones y métodos de pandas son útiles cuando se trata de datos que faltan.
df.info()
Descripción: Un método de DataFrame que devuelve un resumen conciso del marco de datos, incluido un "recuento no nulo", que le ayuda a conocer el número de valores que faltan
Ejemplo:
Descripción: pd.isna() es una función de pandas que devuelve una matriz booleana del mismo tamaño indicando si cada valor es nulo (también puede utilizar pd.isnull() como alias). Tenga en cuenta que esta función también existe como método en DataFrame. Ejemplo:
Descripción: Una función pandas que devuelve una matriz booleana del mismo tamaño indicando si cada valor NO es nulo (también puede utilizar pd.notnull() como alias). Tenga en cuenta que esta función también existe como método en DataFrame.
Ejemplo:
Descripción: Un método de DataFrame que rellena los valores que faltan utilizando el método especificado Ejemplo:
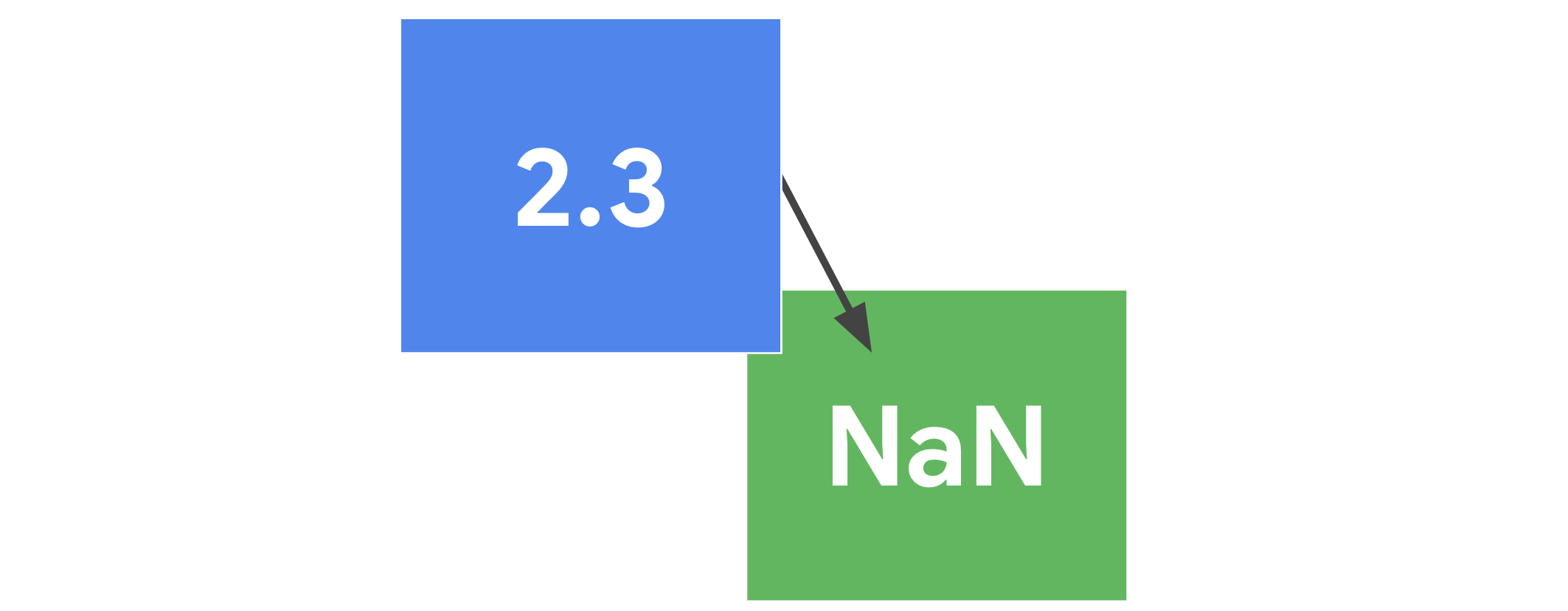
df.replace()
Descripción: Un método de DataFrame que sustituye valores especificados por otros valores especificados. También puede aplicarse a pandas Series. Ejemplo:
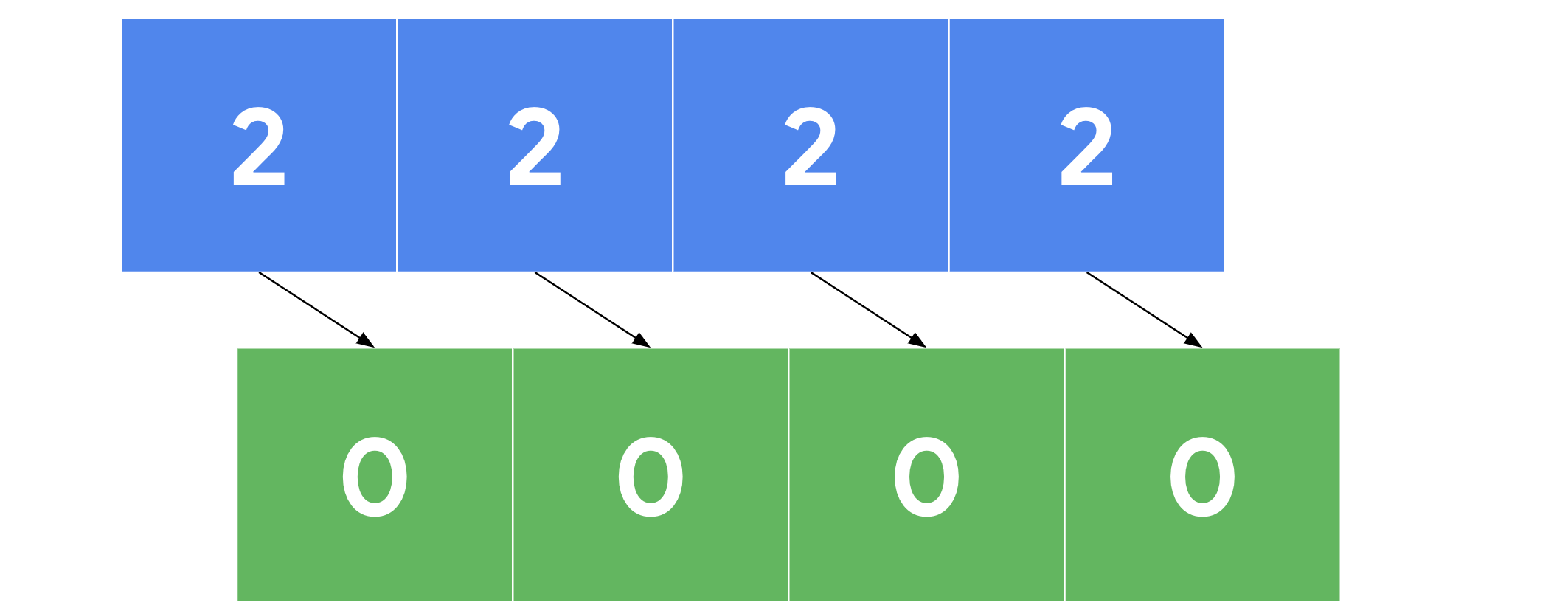
df.dropna()
Descripción: Un método de DataFrame que elimina las filas o columnas que contienen valores perdidos, dependiendo del eje que se especifique. Ejemplo:
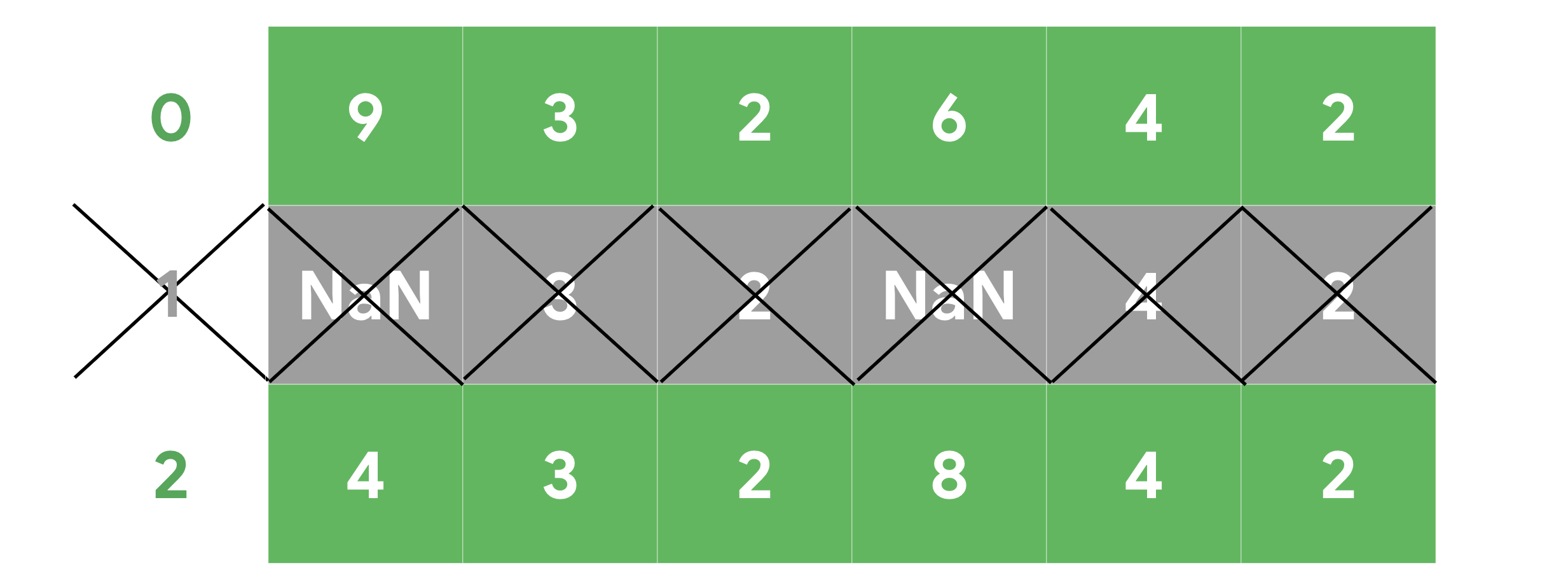
Valores atípicos
Las siguientes herramientas son útiles cuando se trata de valores atípicos en un conjunto de datos.
df.describe()
Descripción: Un método de DataFrame que devuelve estadísticas generales sobre el marco de datos que pueden ayudar a determinar los valores atípicos Ejemplo:
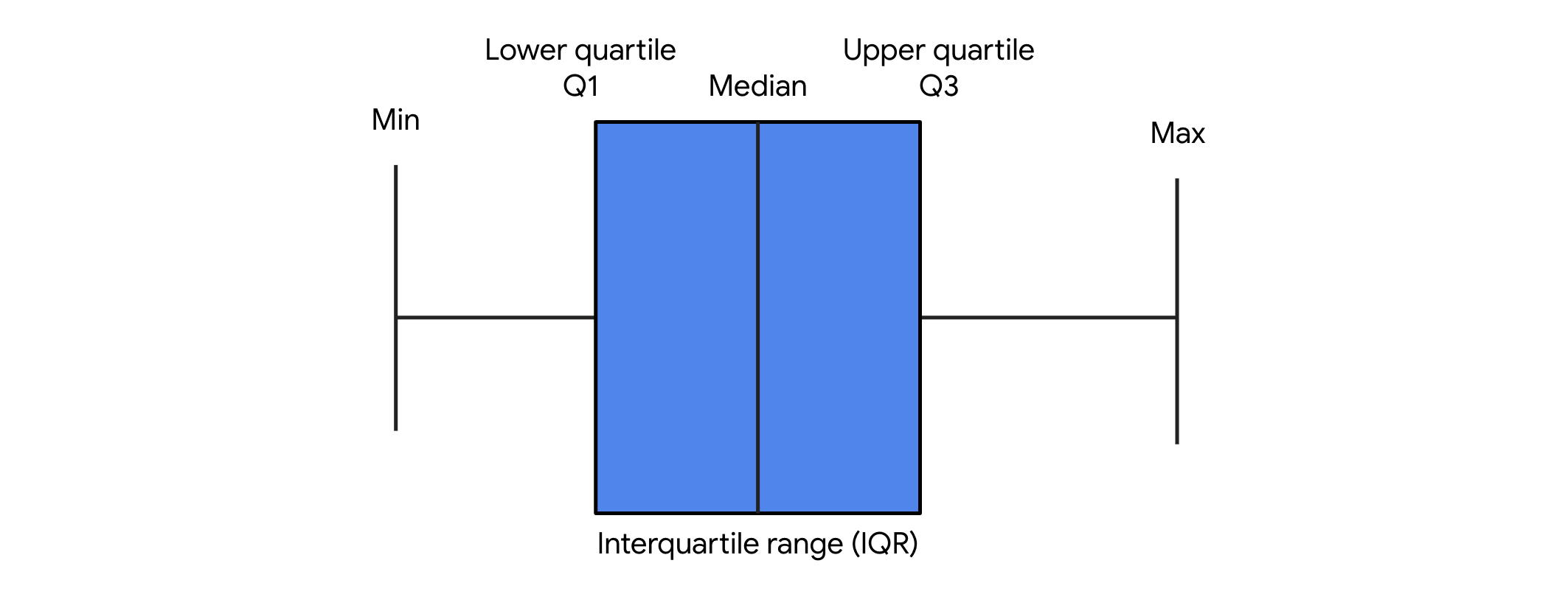
Descripción: Una función de seaborn que genera un gráfico de caja. Los puntos de datos que superan 1,5 veces el rango intercuartílico se consideran valores atípicos. Ejemplo:
Codificación de etiquetas
Las siguientes herramientas son útiles a la hora de realizar la codificación de etiquetas.
df.astype()
Descripción: Un método de DataFrame que le permite codificar sus datos como un dtype especificado. Tenga en cuenta que este método también puede utilizarse en objetos Series. Ejemplo:
Descripción: Atributo de Series que devuelve los códigos numéricos de categoría de las series.
Ejemplo:
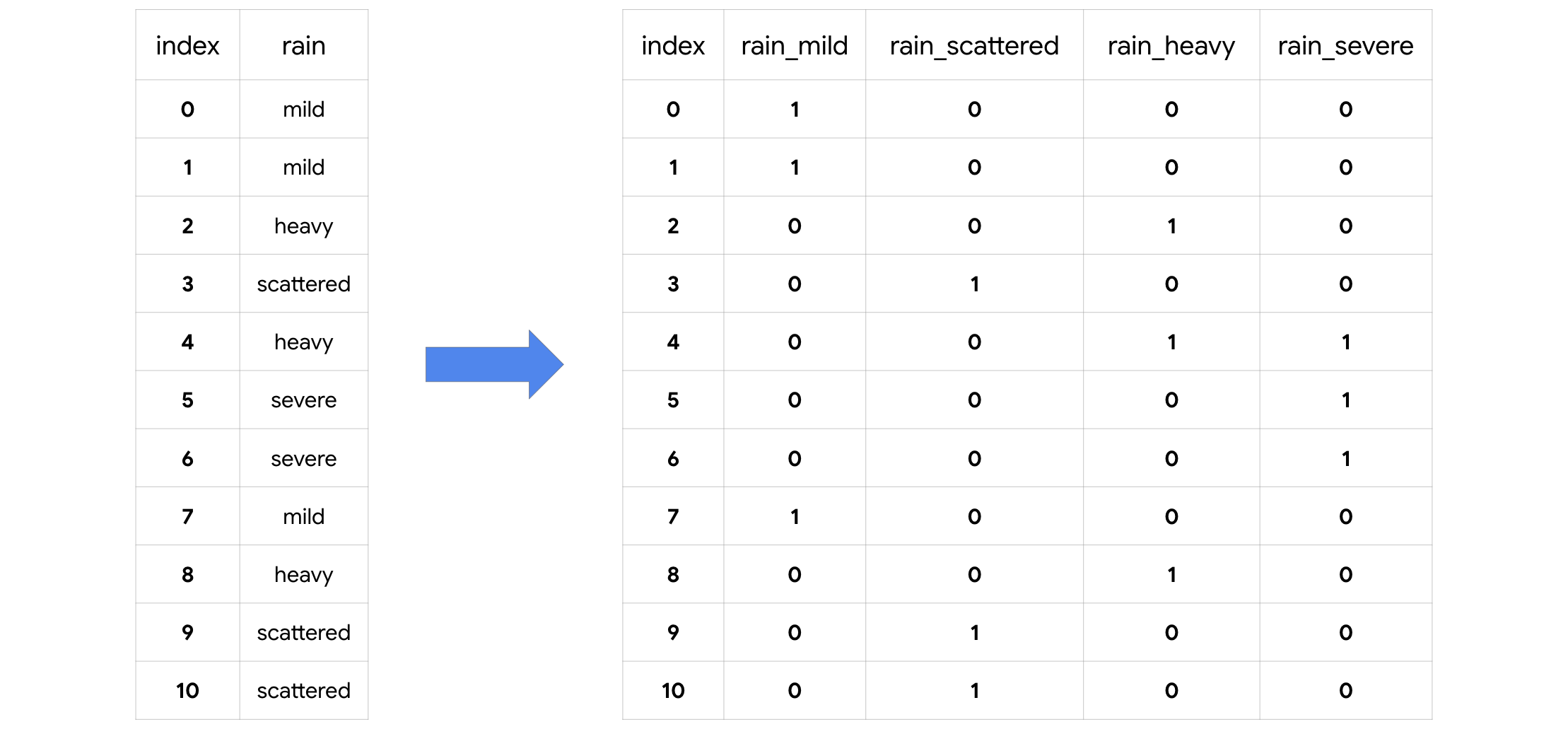
Descripción: Una función que convierte los valores categóricos en nuevas columnas binarias -una para cada categoría diferente Ejemplo:
LabelEncoder()
Descripción: Un transformador de scikit-learn.preprocessing que codifica categorías o etiquetas especificadas con códigos numéricos. Tenga en cuenta que al construir modelos predictivos sólo debe utilizarse en variables objetivo (es decir, datos y ). Ejemplo: Puede utilizarse para normalizar etiquetas:
Puede utilizarse para convertir etiquetas categóricas en numéricas:
>>from sklearn.preprocessing import LabelEncoder
>>>
Data = ['paris', 'paris', 'tokyo', 'amsterdam'] Classes: ['amsterdam', 'paris', 'tokyo'] Encoded classes: [1 1 2 0] New data = [0, 2, 1, 1, 2] Convert new_data to original classes: ['amsterdam', 'tokyo', 'paris', 'paris', 'tokyo']
Puntos clave
Existen muchas herramientas que los profesionales de los datos pueden utilizar para realizar la limpieza de datos en una amplia gama de datos. La información que aprenda de los datos que faltan, los valores atípicos y la transformación de datos categóricos en numéricos le ayudará a preparar conjuntos de datos para su posterior análisis a lo largo de su carrera.



No hay comentarios.:
Publicar un comentario