
Fuente: Google & Coursera.
Guía de referencia: Cómo tratar los valores atípicos
Quizá quieras guardar una copia de esta guía para futuras consultas. Puede utilizarla como recurso para prácticas adicionales o en sus futuros proyectos profesionales. Para acceder a una versión descargable de este elemento del curso, haga clic en el enlace que aparece a continuación y seleccione "Usar plantilla."
Guía de referencia: Cómo tratar los valores atípicos
O
Si no dispone de una cuenta de Google, puede descargar el elemento directamente desde el siguiente archivo adjunto.
Anteriormente, has visto dos vídeos sobre cómo detectar valores atípicos y por qué su tratamiento puede ser una parte importante de la limpieza de datos. En este punto, es probable que tenga una buena comprensión de esto. Es importante no sólo detectar los valores atípicos, sino también tener un plan para ellos.
Eso es precisamente lo que revisará en esta lectura. Una vez detectados los valores atípicos en el conjunto de datos -ya sean globales, contextuales o colectivos-, ¿cómo tratarlos? En lo que respecta al Análisis exploratorio de datos (EDA), existen tres formas principales de tratar los valores atípicos: eliminarlos, reasignarlos o dejarlos como están.
Mantener los valores atípicos tal como están, eliminarlos o reasignarlos es una decisión que se toma en cada conjunto de datos. Para ayudarle a tomar la decisión, puede empezar con estas directrices generales:
Elimínelos: Si está seguro de que los valores atípicos son equivocaciones, erratas o errores y el conjunto de datos se utilizará para modelado o aprendizaje automático, entonces es más probable que decida eliminar los valores atípicos. De las tres opciones, ésta es la que menos utilizará.
Reasignarlos: Si el conjunto de datos es pequeño y/o los datos se utilizarán para el modelado o el aprendizaje automático, es más probable que elija una ruta de derivación de nuevos valores para reemplazar los valores atípicos.
Dejarlos: Para un conjunto de datos en el que se planea hacer EDA/análisis y nada más, o para un conjunto de datos que se está preparando para un modelo que es resistente a los valores atípicos, lo más probable es que los deje.
En los vídeos sobre valores atípicos se explica detalladamente cómo tratar los valores atípicos cuando los deja en el conjunto de datos. En esta lectura, usted aprenderá acerca de algunas técnicas para eliminar y reasignar los valores atípicos.
1. Borrarlos.
Para una forma de eliminar valores atípicos, recuerde la codificación que vio en el video tutorial sobre valores atípicos. En ese video, el instructor codificó un Diagrama de caja para ayudarlo a visualizar dos valores atípicos diferentes, como se muestra aquí:
Nota: El siguiente bloque de código no es interactivo.
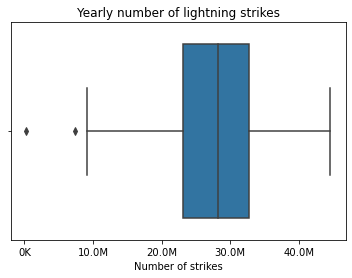
El instructor luego usó el siguiente código para encontrar el límite inferior-8.6M.
>>>Lower limit is: 8585016.625
A continuación, se utilizó una máscara booleana para filtrar el marco de datos de modo que sólo contuviera filas en las que el número de huelgas fuera inferior al límite inferior.
>>>
number_of_strikes year 0 15620068 2020 2 44600989 2018 3 35095195 2017 4 41582229 2016 5 37894191 2015 6 34919173 2014 7 27600898 2013 8 28807552 2012 9 31392058 2011 10 29068965 2010 11 30100585 2009 12 29790934 2008 13 30529064 2007 14 33292382 2006 15 38168699 2005 16 40023951 2004 17 39092327 2003 18 29916767 2002 19 25470095 2001 20 26276135 2000 21 27758681 1999 22 28802221 1998 23 26986915 1997 24 26190094 1996 25 22763540 1995 26 25094010 1994 27 24206929 1993 28 16371876 1992 29 16900934 1991 30 15839052 1990 31 14245186 1989 32 9150440 1988
A continuación, considerará reasignar los valores atípicos derivando nuevos valores que se ajusten mejor al conjunto de datos.
2. Reasignarlos.
En lugar de eliminar los valores atípicos, siempre puede reasignarlos, es decir, cambiar los valores por otros que se ajusten a la distribución general del conjunto de datos. Hay dos formas comunes de hacerlo, pero se pueden utilizar muchas formas diferentes, dependiendo de su caso de uso:
1. Cree un suelo y un techo en un cuantil: Por ejemplo, puede colocar muros en los percentiles 90 y 10 de la distribución de los valores de los datos. Cualquier valor por encima de la marca del 90% o por debajo de la marca del 10% se cambian para encajar dentro de las paredes que establezca. He aquí un ejemplo de cómo podría ser ese código:
2. Imputar la media: En algunos casos, puede ser mejor reasignar todos los valores atípicos para que coincidan con la mediana o el valor medio. Esto garantizará que la mediana y la distribución se basen únicamente en los valores no atípicos, excluyendo los valores atípicos originales. La imputación o reasignación de valores puede ser bastante sencilla si ya ha encontrado los valores atípicos. El siguiente bloque de código calcula la mediana de los valores mayores que el límite inferior. A continuación, imputa la mediana de los valores inferiores al límite inferior.
Nota: Fuera de EDA, el Aprendizaje automático y el modelado de regresión tienen variaciones más complejas al tratar con valores atípicos. Aprenderá más sobre estos temas más adelante.
Puntos clave
Después de detectar los valores atípicos en un conjunto de datos, es esencial que determine una estrategia para manejarlos. Debido a que cada conjunto de datos y problema basado en datos es diferente, su estrategia variará. En la mayoría de los casos, tendrá que elegir entre eliminar, reasignar o dejar los valores atípicos.






No hay comentarios.:
Publicar un comentario