
Lo más destacado para Scikit-Learn 1.7
¡Nos complace anunciar el lanzamiento de Scikit-Learn 1.7! Muchas correcciones de errores y se agregaron mejoras, así como algunas nuevas características clave. Debajo de nosotros Detalle los aspectos más destacados de esta versión. Para una lista exhaustiva de Todos los cambios , consulte las notas de la versión .
Para instalar la última versión (con PIP):
>>pip install --upgrade scikit-learn
o con conda:
>>conda install -c conda-forge scikit-learn
Representación HTML de estimador mejorada
La representación HTML de los estimadores ahora incluye una sección que contiene la lista de
parámetros y sus valores. Los parámetros no predeterminados se destacan en naranja. Una copia
El botón también está disponible para copiar el nombre del parámetro "totalmente calificado" sin el
Necesito llamar al get_params método. Es particularmente útil al definir un
Grid de parámetros para una búsqueda de cuadrícula o una búsqueda aleatoria con una tubería compleja.
Vea el ejemplo a continuación y haga clic en los diferentes bloques del estimador para ver el Representación HTML mejorada.
>>from sklearn.linear_model import LogisticRegression
>>from sklearn.pipeline import make_pipeline
>>from sklearn.preprocessing import StandardScaler
>>model = make_pipeline(StandardScaler(with_std=False), LogisticRegression(C=2.0))
>>model
Tubería
?
no
Parámetros
pasos [('estándaresscaler', ...), ('LogisticRegression', ...)]
transform_input Ninguno
memoria Ninguno
verboso FALSO
Estandarias
?
Parámetros
Copiar Verdadero
With_mean Verdadero
with_std FALSO
Recreación logística
?
Parámetros
pena 'L2'
dual FALSO
peaje 0.0001
do 2.0
Fit_intercept Verdadero
intercept_caling 1
class_weight Ninguno
random_state Ninguno
solucionador 'lbfgs'
max_iter 100
múltiple 'Depreciado'
verboso 0
Warm_Start FALSO
n_jobs Ninguno
l1_ratio Ninguno
Establecimiento de validación personalizada para estimadores de impulso de gradiente basado en histogramas
El ensemble.HistGradientBoostingClassifiery
ensemble.HistGradientBoostingRegressor ahora admite pasar directamente una costumbre
Validación establecida para detener temprano al fit método, usando el X_val, y_val, y
sample_weight_val parámetros.
En pipeline.Pipeline, el conjunto de validación X_val se puede transformar a lo largo
con X usando el transform_input parámetro.
>>import sklearn
>>from sklearn.datasets import make_classification
>>from sklearn.ensemble import HistGradientBoostingClassifier
>>from sklearn.model_selection import train_test_split
>>from sklearn.pipeline import Pipeline
>>from sklearn.preprocessing import StandardScaler
>>sklearn.set_config(enable_metadata_routing=True)
>>X, y = make_classification(random_state=0)
>>X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=0)
>>clf = HistGradientBoostingClassifier()
>>clf.set_fit_request(X_val=True, y_val=True)
>>model = Pipeline([("sc", StandardScaler()), ("clf", clf)], transform_input=["X_val"])
>>model.fit(X, y, X_val=X_val, y_val=y_val)
Tubería
?
I
Parámetros
pasos [('sc', ...), ('clf', ...)]
transform_input ['X_val']
memoria Ninguno
verboso FALSO
Estandarias
?
Parámetros
Copiar Verdadero
With_mean Verdadero
with_std Verdadero
Histgradient BoostingClassifier
?
Parámetros
pérdida 'Log_loss'
aprendizaje_rate 0.1
max_iter 100
max_leaf_nodes 31
max_depth Ninguno
min_samples_leaf 20
l2_regularización 0.0
max_features 1.0
max_bins 255
categórico_Features 'from_dtype'
monotonic_cst Ninguno
interacción_cst Ninguno
Warm_Start FALSO
Early_stopping 'auto'
tanteo 'pérdida'
Validation_Fraction 0.1
n_iter_no_change 10
peaje 1e-07
verboso 0
random_state Ninguno
class_weight Ninguno
Trazar curvas ROC de resultados de validación cruzada
La clase metrics.RocCurveDisplay tiene un nuevo método de clase from_cv_results
que permite trazar fácilmente múltiples curvas ROC de los resultados de
model_selection.cross_validate.
>>from sklearn.datasets import make_classification
>>from sklearn.linear_model import LogisticRegression
>>from sklearn.metrics import RocCurveDisplay
>>from sklearn.model_selection import cross_validate
>>X, y = make_classification(n_samples=150, random_state=0)
>>clf = LogisticRegression(random_state=0)
>>cv_results = cross_validate(clf, X, y, cv=5, return_estimator=True, return_indices=True)
>>_ = RocCurveDisplay.from_cv_results(cv_results, X, y) 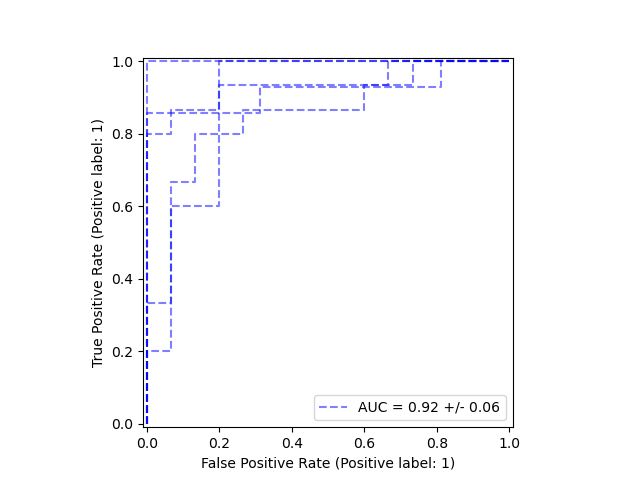
API API de matriz
Se han actualizado varias funciones para admitir entradas compatibles con la API de matriz desde
Versión 1.6, especialmente métricas de la sklearn.metrics módulo.
Además, ya no es necesario instalar el array-api-compat Paquete para usar
El soporte de API de matriz experimental en Scikit-Learn.
Consulte la de soporte de la API de matriz para obtener instrucciones para usar Scikit-Learn con bibliotecas compatibles con API de matriz como Pytorch o Cupy.
Consistencia de API mejorada de Perceptron de múltiples capas
El neural_network.MLPRegressor tiene un nuevo parámetro loss y ahora apoya
La pérdida de "Poisson" además de la pérdida predeterminada "Squared_error".
Además, el neural_network.MLPClassifiery
neural_network.MLPRegressor Los estimadores ahora admiten pesos de muestra.
Se han realizado estas mejoras para mejorar la consistencia de estos estimadores.
Con respecto a los otros estimadores en Scikit-Learn.
Migración hacia matrices escasas
Para preparar la migración escasa de matrices dispersas a matrices dispersas , Todos los estimadores de Scikit-Learn que aceptan matrices dispersas como entrada ahora también aceptan matrices dispersas.
Tiempo de ejecución total del script: (0 minutos 0.206 segundos)


No hay comentarios.:
Publicar un comentario